
Go Scheduler Deep Dive: GMP Model, Preemption và Netpoll
April 4, 2026

Bài viết này là bản dịch và bổ sung giải thích từ bài gốc Go Scheduler của nghiant3223. Nội dung được sử dụng cho mục đích học tập, phi thương mại. Mọi quyền thuộc về tác giả gốc.
Giới thiệu
Go ra mắt năm 2009 bởi Google, nhanh chóng trở thành một trong những ngôn ngữ phổ biến nhất cho backend development và distributed systems. Một trong những điểm mạnh nổi bật nhất của Go chính là concurrency model dựa trên goroutines — lightweight user-space threads được Go runtime quản lý hoàn toàn, thay vì phụ thuộc vào OS threads truyền thống.
Goroutine: Là đơn vị thực thi nhẹ (lightweight execution unit) do Go runtime quản lý. Mỗi goroutine chỉ tốn khoảng 2-8 KB stack memory ban đầu, so với 1-8 MB cho một OS thread. Một chương trình Go có thể chạy hàng triệu goroutines đồng thời.
Concurrency: Là khả năng xử lý nhiều tasks đồng thời (not necessarily in parallel). Go cung cấp concurrency thông qua goroutines và channels, cho phép viết code đơn giản nhưng hiệu quả cho các bài toán I/O-bound và CPU-bound.
Go cũng cung cấp channels — cơ chế communication và synchronization giữa các goroutines, theo triết lý nổi tiếng:
"Don't communicate by sharing memory; share memory by communicating."
Hiểu cách Go scheduler hoạt động bên trong giúp developer:
- Viết concurrent code hiệu quả hơn
- Debug performance issues liên quan đến scheduling
- Tối ưu I/O-bound và CPU-bound programs
- Hiểu rõ behavior của runtime khi goroutines bị block
Nội dung bài viết
Bài viết sẽ đi sâu vào các chủ đề sau:
- Compilation và Go Runtime — quá trình biên dịch và vai trò của runtime
- Primitive Scheduler đến GMP Model — evolution của scheduler design
- GMP Model chi tiết — cấu trúc G, M, P và cách chúng phối hợp
- Bootstrap và tạo Goroutine — quá trình khởi tạo chương trình Go
- Schedule Loop — vòng lặp scheduling chính
- Preemption — cooperative và non-cooperative preemption
- System Call handling — cách scheduler xử lý syscalls
- Network I/O và Netpoll — I/O multiplexing trong Go runtime
- GC, Runtime Functions — garbage collection và các hàm runtime quan trọng
Compilation và Go Runtime
Quá trình biên dịch
Go compiler biến source code thành executable binary qua ba giai đoạn chính:
.go source ---> .s assembly ---> .o object ---> executable binary
(compile) (assemble) (link)
- Compile: Go source code (
.go) được chuyển thành assembly (.s) cho target platform - Assemble: Assembly code được chuyển thành object files (
.o) - Link: Object files được link với nhau và với Go runtime để tạo thành executable binary cuối cùng
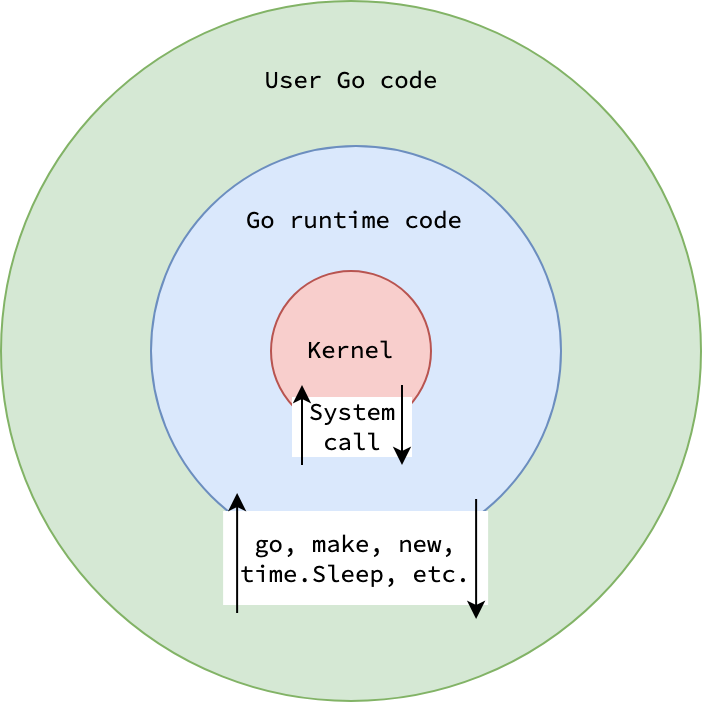
Điểm quan trọng là Go statically links runtime vào mỗi binary. Điều này có nghĩa mọi Go binary đều chứa toàn bộ runtime bên trong — bao gồm scheduler, garbage collector, và memory allocator.
Go Runtime là gì?
Go Runtime: Là tập hợp các functions và data structures cung cấp scheduling, memory management, và garbage collection. Runtime được viết bằng Go và assembly, nằm trong
runtimepackage của Go standard library.
Go runtime không phải là virtual machine (như JVM). Nó là một library được compile và link trực tiếp vào application binary:
+--------------------------------------------------+
| Executable Binary |
| |
| +-------------------+ +---------------------+ |
| | Application Code | | Go Runtime | |
| | | | | |
| | - main() | | - Scheduler (GMP) | |
| | - your packages | | - Memory Allocator | |
| | - goroutines | | - Garbage Collector | |
| | | | - Netpoll | |
| +-------------------+ +---------------------+ |
| |
+--------------------------------------------------+
Compiler thay thế keywords bằng runtime calls
Go compiler tự động thay thế một số keywords và built-in functions bằng các lời gọi đến runtime:
| Keyword / Function | Runtime Call | Mô tả |
|---|---|---|
go | runtime.newproc | Tạo goroutine mới |
new | runtime.newobject | Allocate memory cho object |
make (channel) | runtime.makechan | Tạo channel mới |
make (map) | runtime.makemap | Tạo map mới |
make (slice) | runtime.makeslice | Tạo slice mới |
Ví dụ, khi bạn viết:
go myFunction()
Compiler sẽ chuyển thành:
runtime.newproc(myFunction)
Các hàm đặc biệt trong runtime
Một số functions trong runtime không có Go implementation — chúng tồn tại hoàn toàn ở assembly level hoặc được compiler xử lý đặc biệt:
Compiler Intrinsic: Là function mà compiler nhận diện và thay thế trực tiếp bằng machine code tối ưu, thay vì thực hiện function call thông thường. Trong Go,
getglà một compiler intrinsic.
-
getg()— Lấy pointer đến goroutine struct (G) hiện tại. Đây là compiler intrinsic, được thay thế bằng assembly instruction đọc G từ TLS (Thread-Local Storage) hoặc dedicated register. Không có Go source code nào implement function này. -
gogo()— Chuyển execution context sang một goroutine khác. Hoàn toàn được viết bằng assembly vì cần thao tác trực tiếp với CPU registers và stack pointer — điều Go code không thể làm.
//go:linkname directive
//go:linkname: Là compiler directive cho phép một function trong package này liên kết (link) với implementation ở package khác tại link time, bỏ qua Go's normal visibility rules.
Directive này được sử dụng rộng rãi trong standard library để kết nối public API với internal runtime implementation:
// In time package:
//go:linkname Sleep runtime.timeSleep
func Sleep(d Duration)
// Actual implementation lives in runtime package:
// runtime/time.go
func timeSleep(ns int64) {
// ... implementation
}
Khi user gọi time.Sleep(), linker sẽ redirect call đến runtime.timeSleep(). Cơ chế này giúp runtime giữ implementation internal trong khi vẫn expose clean public API.
Từ Primitive Scheduler đến GMP Model
Threading Models
Trước khi đi vào Go scheduler, cần hiểu ba mô hình threading cơ bản mà các ngôn ngữ lập trình sử dụng để map user-space threads lên kernel threads.
User-space Thread: Thread được quản lý bởi runtime/library ở user space, kernel không biết đến sự tồn tại của chúng. Goroutines trong Go là user-space threads.
Kernel Thread: Thread được quản lý trực tiếp bởi OS kernel, có thể được schedule lên CPU cores. Kernel threads tốn nhiều tài nguyên hơn user-space threads.
N:1 Model (Many-to-One)
Nhiều user-space threads được map lên một kernel thread duy nhất.
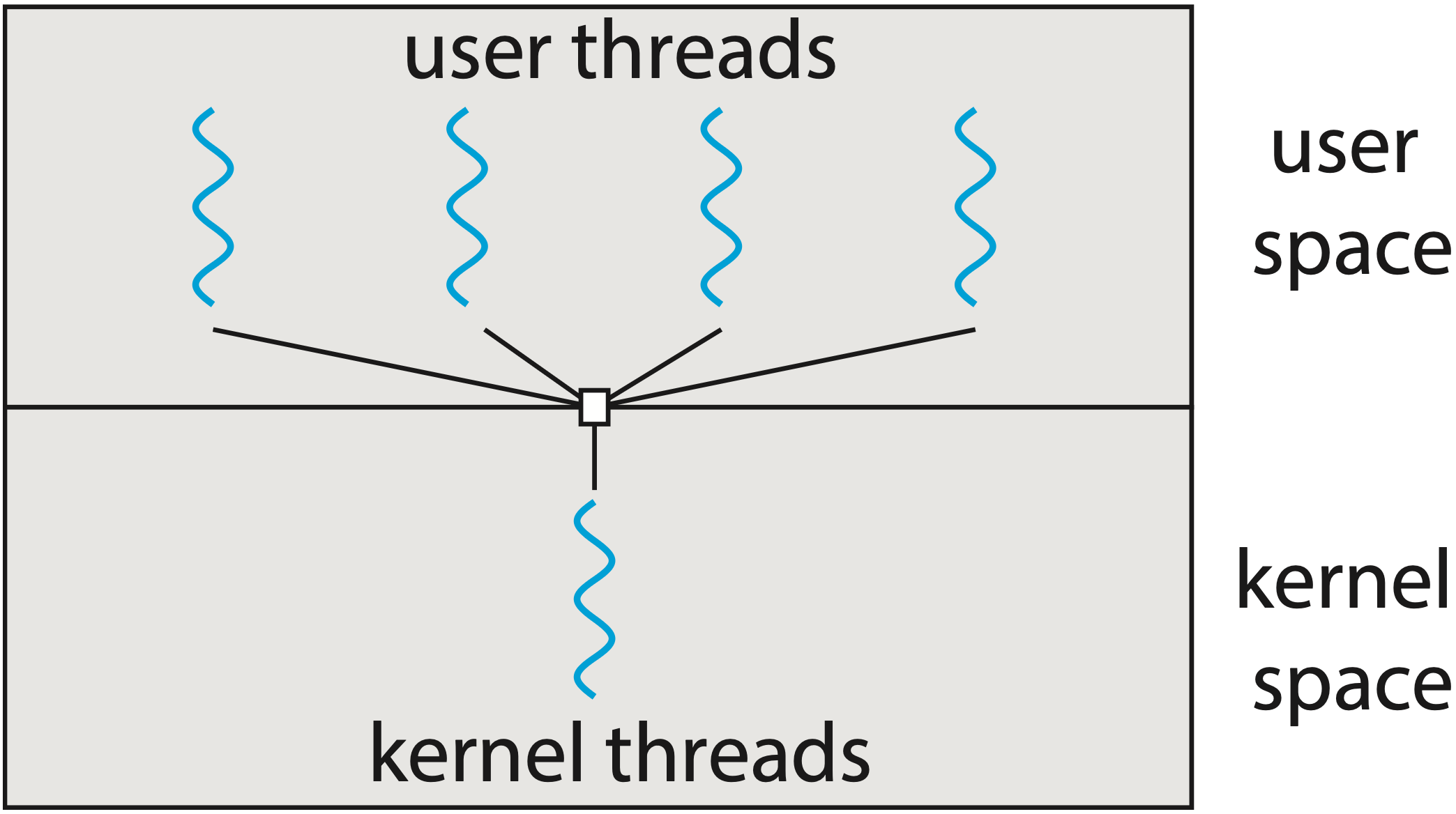
- Ưu điểm: Context switch nhanh (không cần syscall), implementation đơn giản
- Nhược điểm: Không tận dụng được multicore/multiprocessor. Khi một thread thực hiện blocking syscall, tất cả threads đều bị block vì chúng chia sẻ cùng một kernel thread
1:1 Model (One-to-One)
Mỗi user-space thread được map trực tiếp lên một kernel thread.
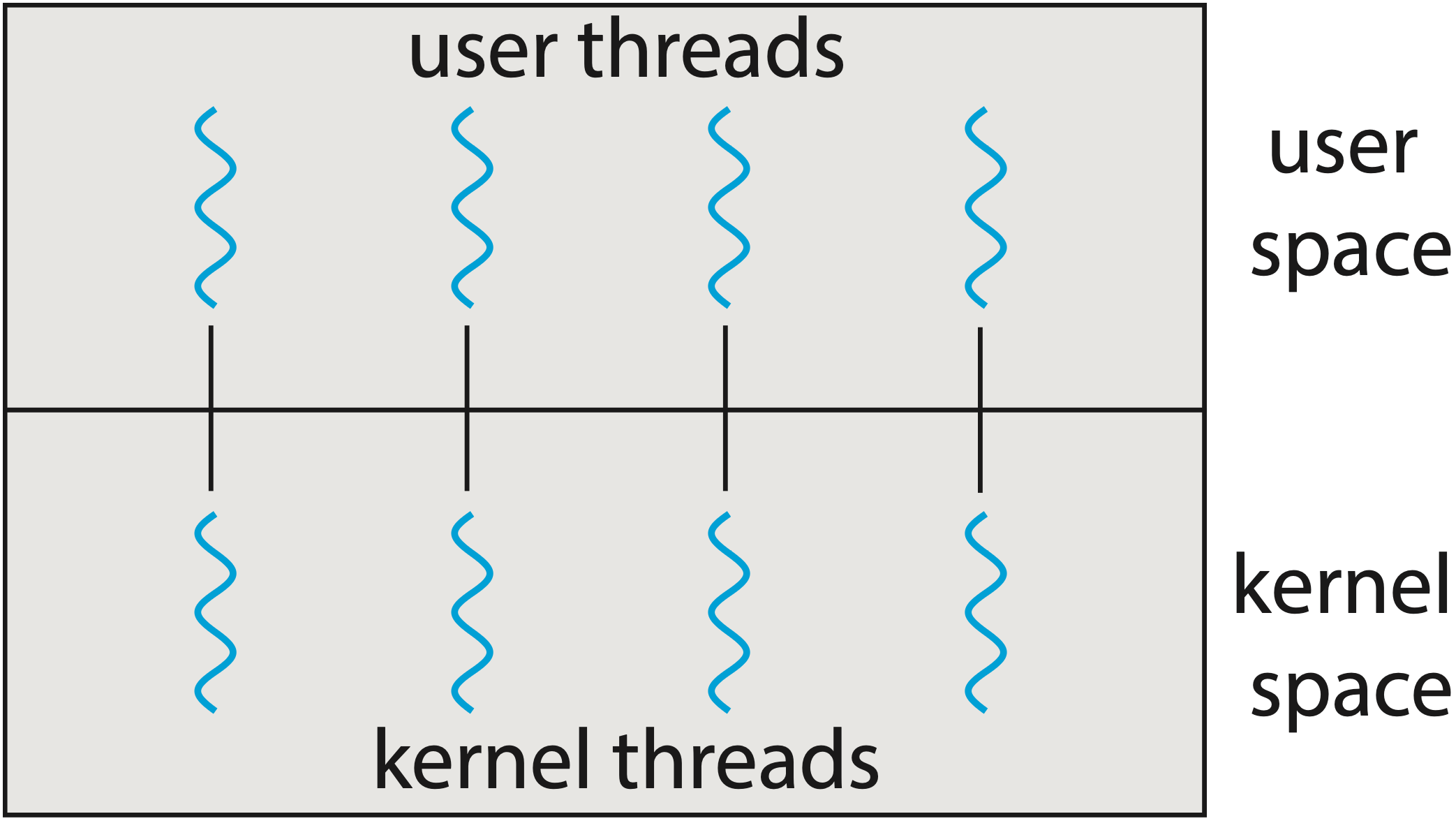
- Ưu điểm: True parallelism trên multicore systems. Một thread block không ảnh hưởng threads khác
- Nhược điểm: Thread creation tốn kém (~1-8 MB stack mỗi thread). Context switch qua kernel chậm. Số lượng threads bị giới hạn bởi OS resources
Đây là model mà hầu hết các ngôn ngữ như Java, C++, Rust sử dụng (thông qua pthreads hoặc tương đương).
M:N Model (Many-to-Many)
M user-space threads được map lên N kernel threads (M >= N).
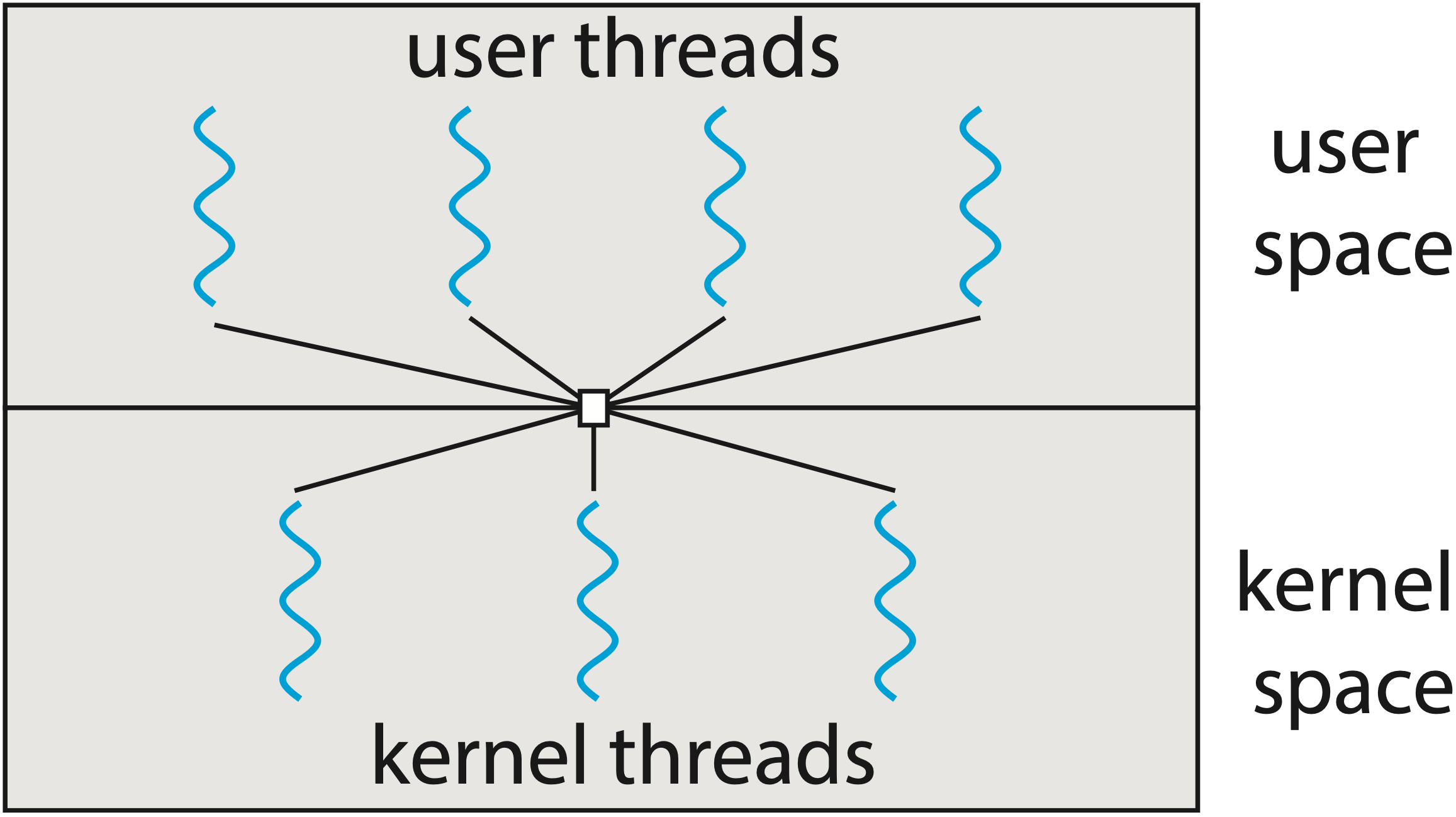
- Ưu điểm: Kết hợp tốt nhất của cả hai models — true parallelism và lightweight thread creation
- Nhược điểm: Phức tạp nhất để implement. Runtime phải tự quản lý scheduling và xử lý edge cases (syscall blocking, thread parking, work stealing...)
Go sử dụng M:N model, với goroutines (G) là user-space threads và OS threads (M) là kernel threads. Go runtime chịu trách nhiệm schedule goroutines lên OS threads một cách hiệu quả.
Primitive Scheduler (trước Go 1.1)
Phiên bản đầu tiên của Go scheduler rất đơn giản — chỉ có hai entities:
- G (Goroutine): Đại diện cho một goroutine
- M (Machine/Thread): Đại diện cho một OS thread
Tất cả goroutines được đặt trong một global run queue duy nhất, được bảo vệ bởi một mutex lock. Mọi M muốn lấy G để chạy đều phải acquire lock này.
+-------+ +-------+ +-------+
| M0 | | M1 | | M2 |
+---+---+ +---+---+ +---+---+
| | |
v v v
+---------------------+
| Global Run Queue |
| (protected by mutex)|
| |
| [G1][G2][G3]...[Gn] |
+---------------------+
Vấn đề của Primitive Scheduler
Năm 2012, Dmitry Vyukov (kỹ sư tại Google) đã phân tích và chỉ ra ba vấn đề nghiêm trọng:
1. Lock Contention (Tranh chấp khóa)
Mọi thao tác trên run queue — push, pop, hoặc thậm chí kiểm tra queue — đều cần acquire global mutex. Khi số lượng M tăng lên, các threads liên tục phải chờ nhau, tạo ra bottleneck nghiêm trọng.
2. Poor Locality (Locality kém)
Goroutines thường xuyên bị chuyển qua lại giữa các threads. Một goroutine được tạo trên M0 có thể chạy trên M1, rồi resume trên M2. Điều này phá hủy cache locality — data mà goroutine cần có thể đã nằm trong L1/L2 cache của thread cũ nhưng không có trong cache của thread mới.
3. Memory Waste (Lãng phí bộ nhớ)
Mỗi M có một mcache (memory cache cho allocation, có thể lên đến 2 MB). Vấn đề là mcache gắn với M, kể cả khi M đang bị block trong syscall và không làm gì cả. Trong thực tế, tỉ lệ active threads so với total threads có thể chỉ là 1:100 — 99 threads đang block nhưng vẫn giữ mcache.
Proposal 1: Local Run Queue
Ý tưởng đầu tiên là cho mỗi M một local run queue riêng:
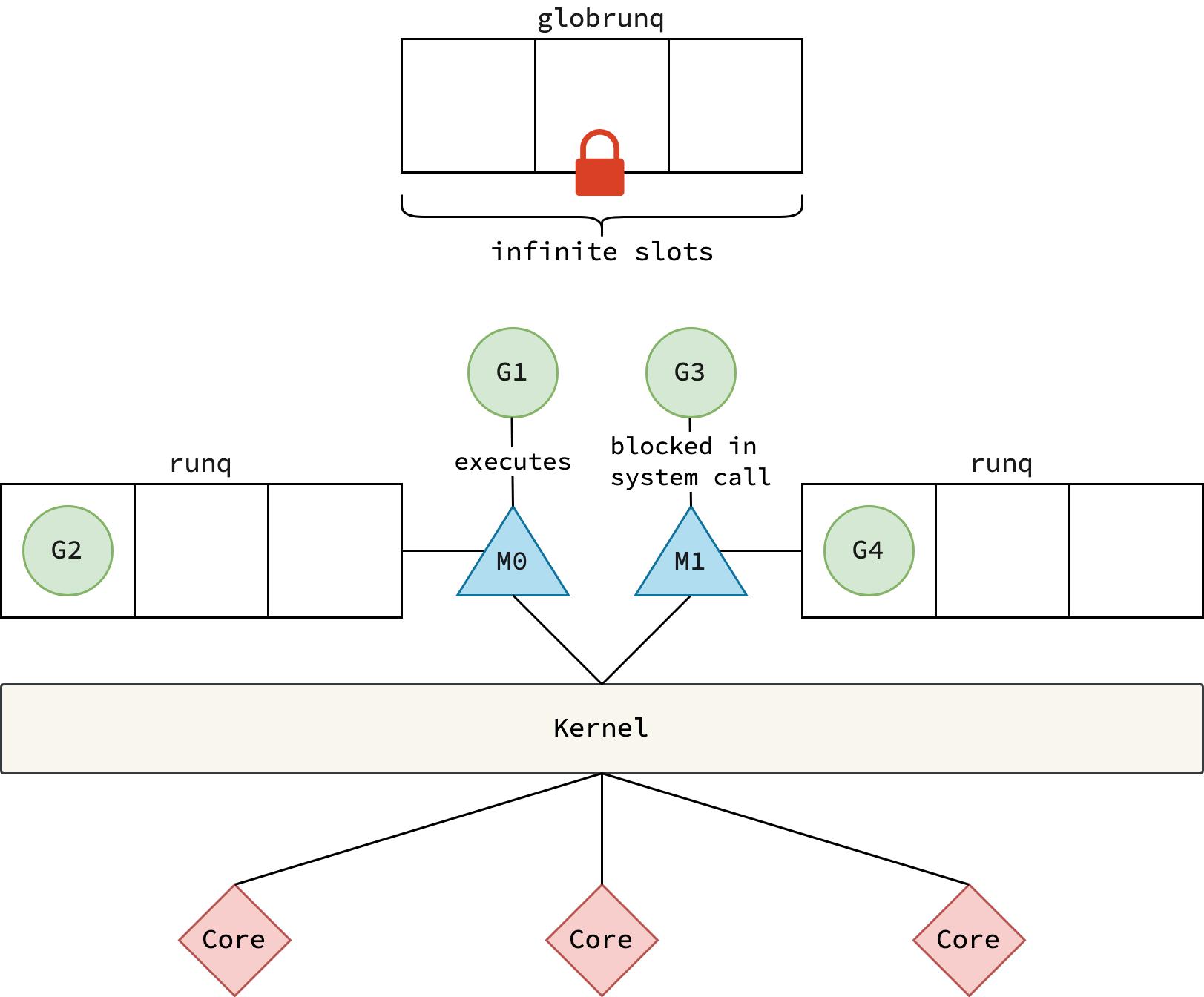
Cách hoạt động:
- Goroutine mới được đẩy vào local queue của M hiện tại (hoặc global queue nếu local queue đầy)
- M ưu tiên lấy G từ local queue trước, rồi mới check global queue
- Nếu cả hai đều trống, thực hiện work stealing — lấy goroutines từ local queue của M khác
Proposal này giải quyết được lock contention (mỗi M có queue riêng) và locality (goroutine có xu hướng chạy trên cùng M đã tạo ra nó). Tuy nhiên, nó không giải quyết memory waste — mcache vẫn gắn với M, và work stealing trở nên tốn kém khi có nhiều M bị block (phải scan qua nhiều idle threads).
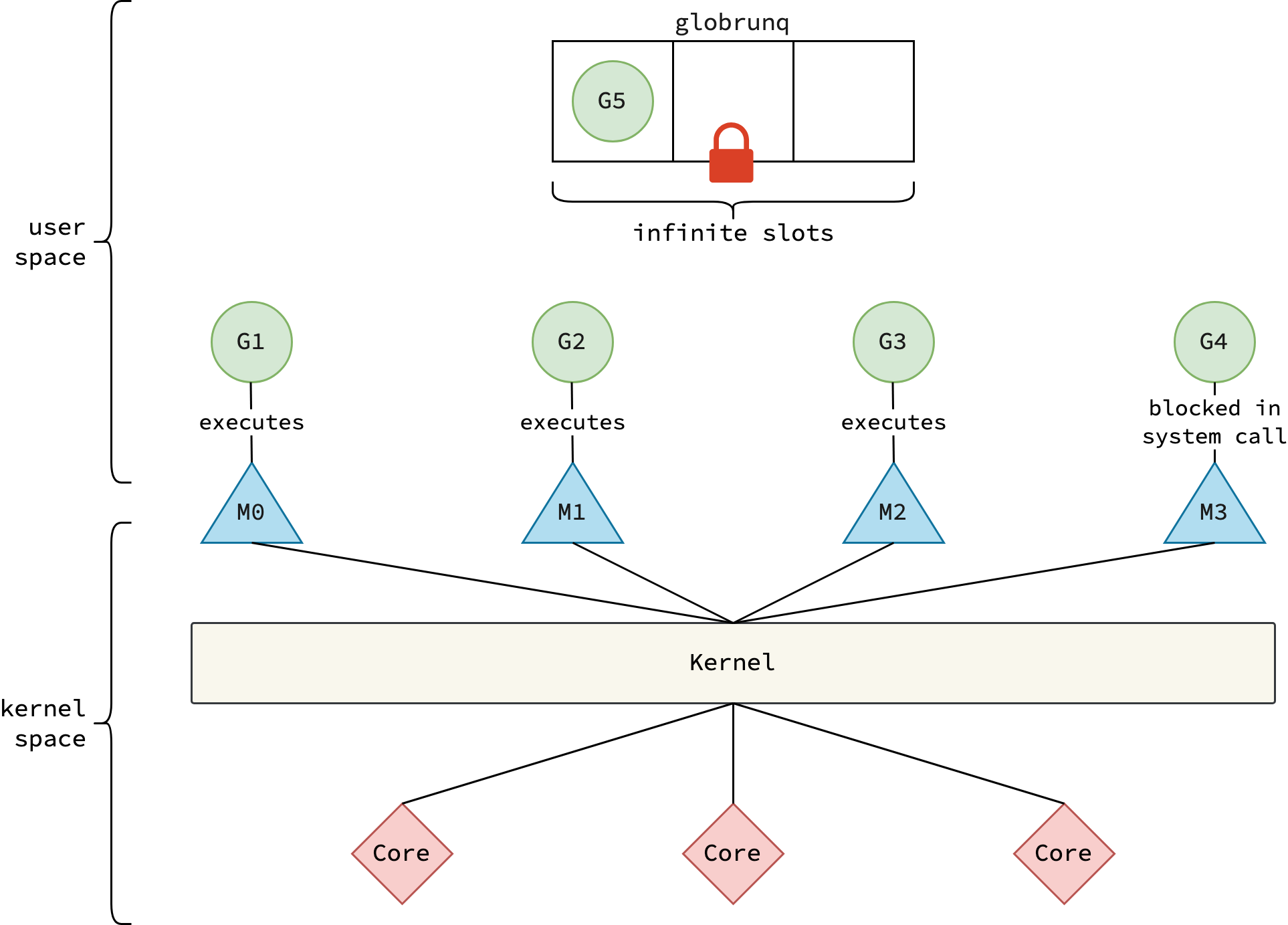
Proposal 2: Logical Processor (P) — GMP Model
Giải pháp cuối cùng là giới thiệu entity thứ ba — P (Processor):
P (Processor): Là logical processor trong GMP model. P giữ local run queue và mcache. Số lượng P được set bằng
GOMAXPROCS(mặc định bằng số CPU cores). M phải acquire một P trước khi có thể thực thi goroutines.
Thay đổi cốt lõi:
- Local run queue và mcache thuộc về P, không phải M
- Khi M bị block trong syscall, P detach khỏi M và attach vào M khác (hoặc tạo M mới)
- Số lượng P giới hạn (thường bằng số CPU cores), nên work stealing chỉ cần scan qua một số P nhỏ — rất hiệu quả
Before (Primitive): After (GMP):
M0 M1 M2 M0--P0 M1--P1
| | | | |
v v v v v
[Global Queue] [LRQ0] [LRQ1]
\ /
[Global Queue]
Thiết kế GMP model giải quyết cả ba vấn đề:
- Lock contention: Mỗi P có local queue riêng, giảm thiểu lock tranh chấp
- Locality: Goroutine thường chạy trên cùng P đã tạo ra nó
- Memory waste: mcache gắn với P (số lượng ít, luôn active), không gắn với M (số lượng nhiều, thường block)
Đây chính là nền tảng của Go scheduler hiện đại, được merge vào Go 1.1 (2013) và tiếp tục được cải tiến đến ngày nay.
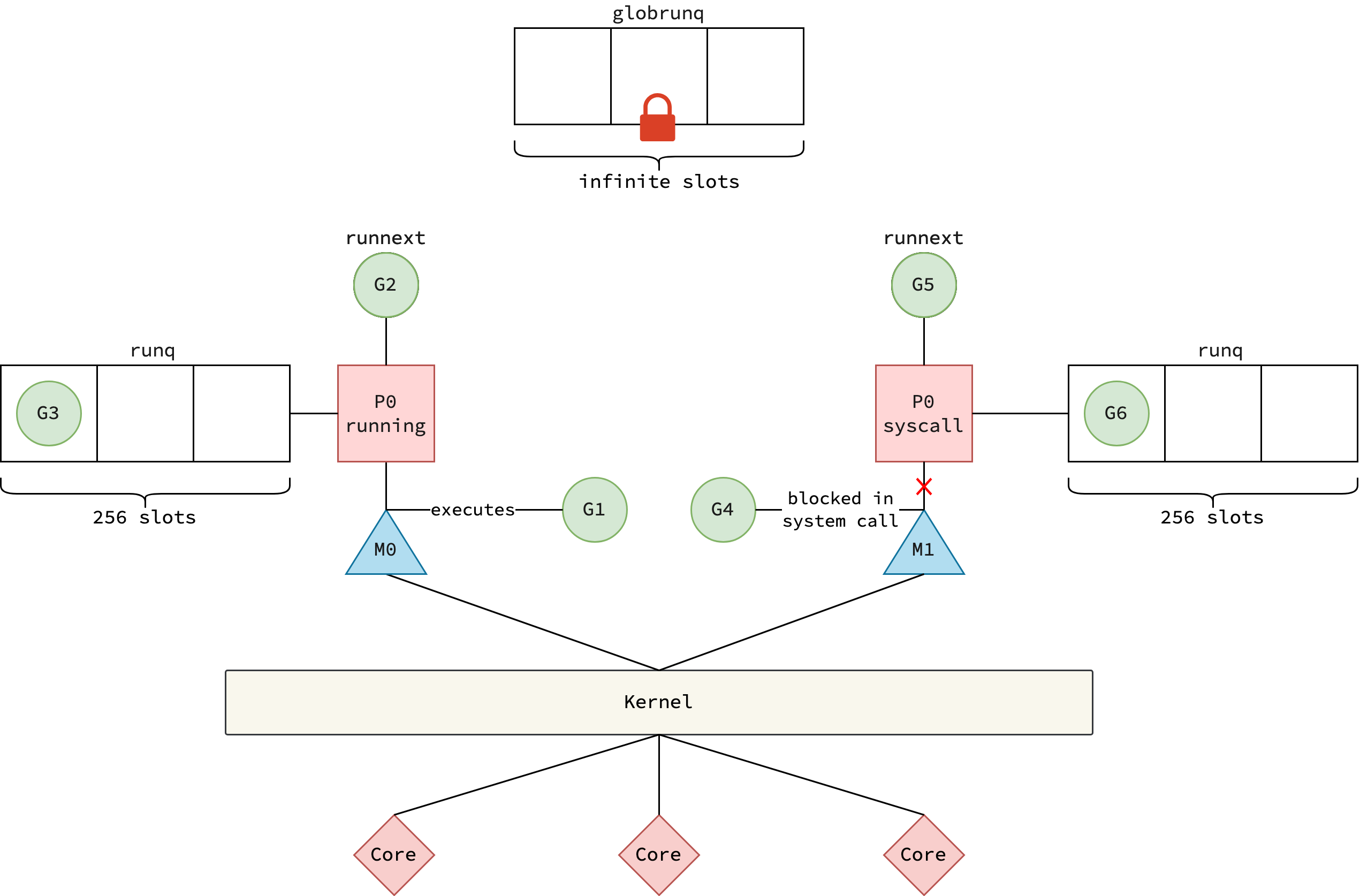
GMP Model
Go scheduler hoạt động dựa trên mô hình GMP — ba thành phần cốt lõi phối hợp với nhau để quản lý hàng nghìn goroutine trên một số lượng hạn chế OS thread.
Goroutine (G): Là đơn vị thực thi nhẹ trong Go, được biểu diễn bởi
gstruct chứa metadata, execution state, stack (khởi tạo 2KB, tự động grow khi cần), và program counter. Khi goroutine hoàn thành, nó được recycle vào free list thay vì bị hủy — chi phí tạo mới thấp hơn nhiều so với OS thread.
Thread/Machine (M): Là OS kernel thread thực sự do hệ điều hành quản lý. Mỗi M có một goroutine đặc biệt gọi là g0 chạy trên system stack (do kernel cấp), dùng để thực thi scheduler code và runtime code. Khi cần schedule goroutine mới, M chuyển sang g0 để thực hiện.
Processor (P): Là logical processor, số lượng được xác định bởi
GOMAXPROCS. Mỗi P sở hữu một local run queue gồmrunnext(1 slot ưu tiên cao nhất) vàrunq(circular queue). Ngoài ra, P còn chứamcacheđể memory allocation và quản lý timers thông qua min-heap.
Goroutine States
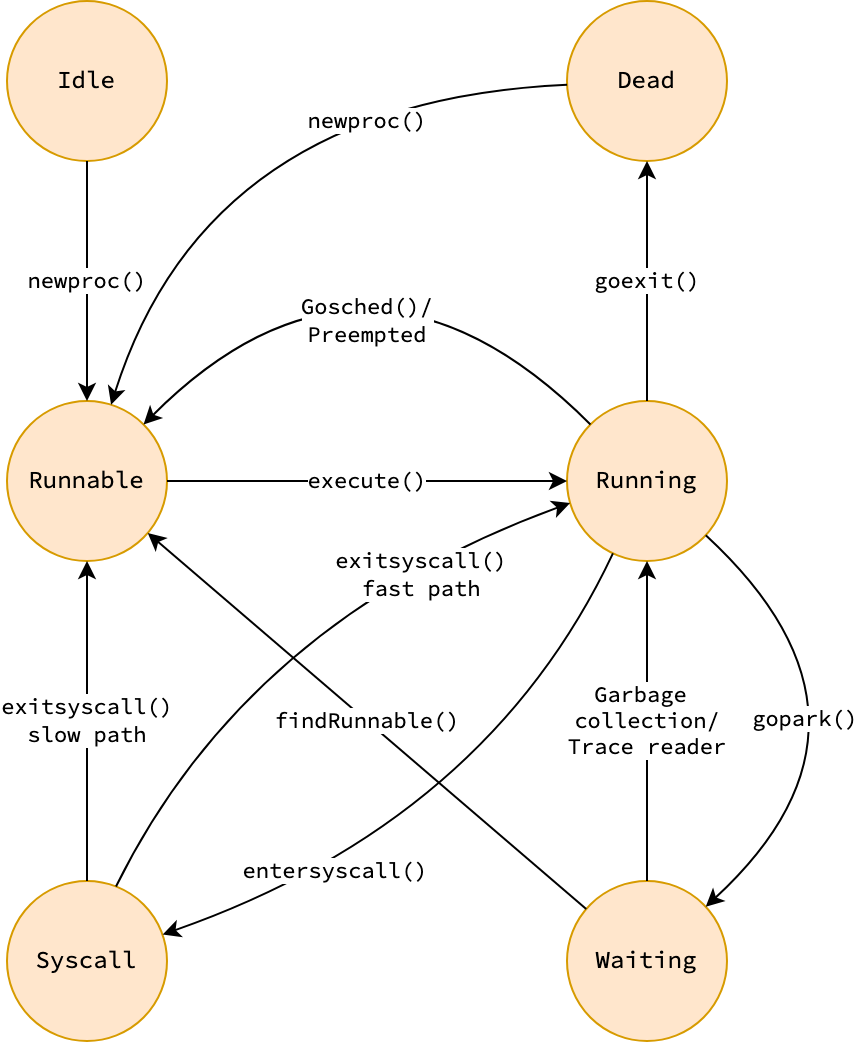
Goroutine có 6 trạng thái chính:
| State | Giá trị | Mô tả |
|---|---|---|
| Idle | _Gidle | Goroutine vừa được allocate, chưa được khởi tạo |
| Runnable | _Grunnable | Đã sẵn sàng chạy, nằm trong run queue, chờ được gán cho M |
| Running | _Grunning | Đang thực thi trên một M, có P gắn kèm |
| Syscall | _Gsyscall | Đang thực hiện system call, không sử dụng stack |
| Waiting | _Gwaiting | Đang bị block bởi runtime (channel, mutex, sleep, I/O) |
| Dead | _Gdead | Đã hoàn thành hoặc vừa được khởi tạo, sẵn sàng recycle |
Thread States
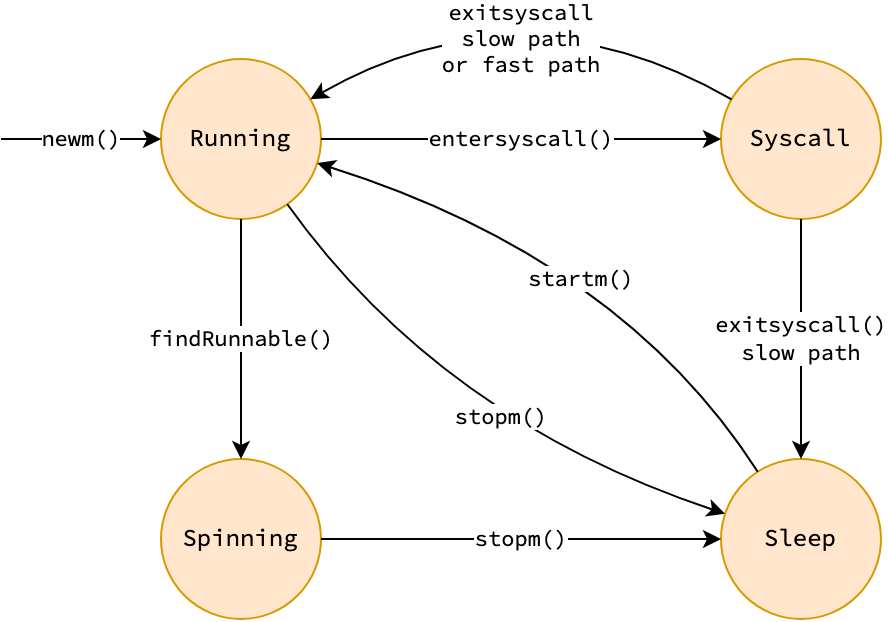
Thread (M) có 4 trạng thái:
| State | Mô tả |
|---|---|
| Running | Đang thực thi Go code hoặc runtime code, có P gắn kèm |
| Syscall | Đang bị block trong system call, P có thể bị tách ra (handoff) |
| Spinning | Đang tìm kiếm goroutine để steal từ P khác. Số lượng spinning thread bị giới hạn: chỉ cho phép khi spinning threads < một nửa số busy processors — tránh lãng phí CPU |
| Sleep | Không có việc làm, nằm trong idle list chờ được đánh thức |
Processor States
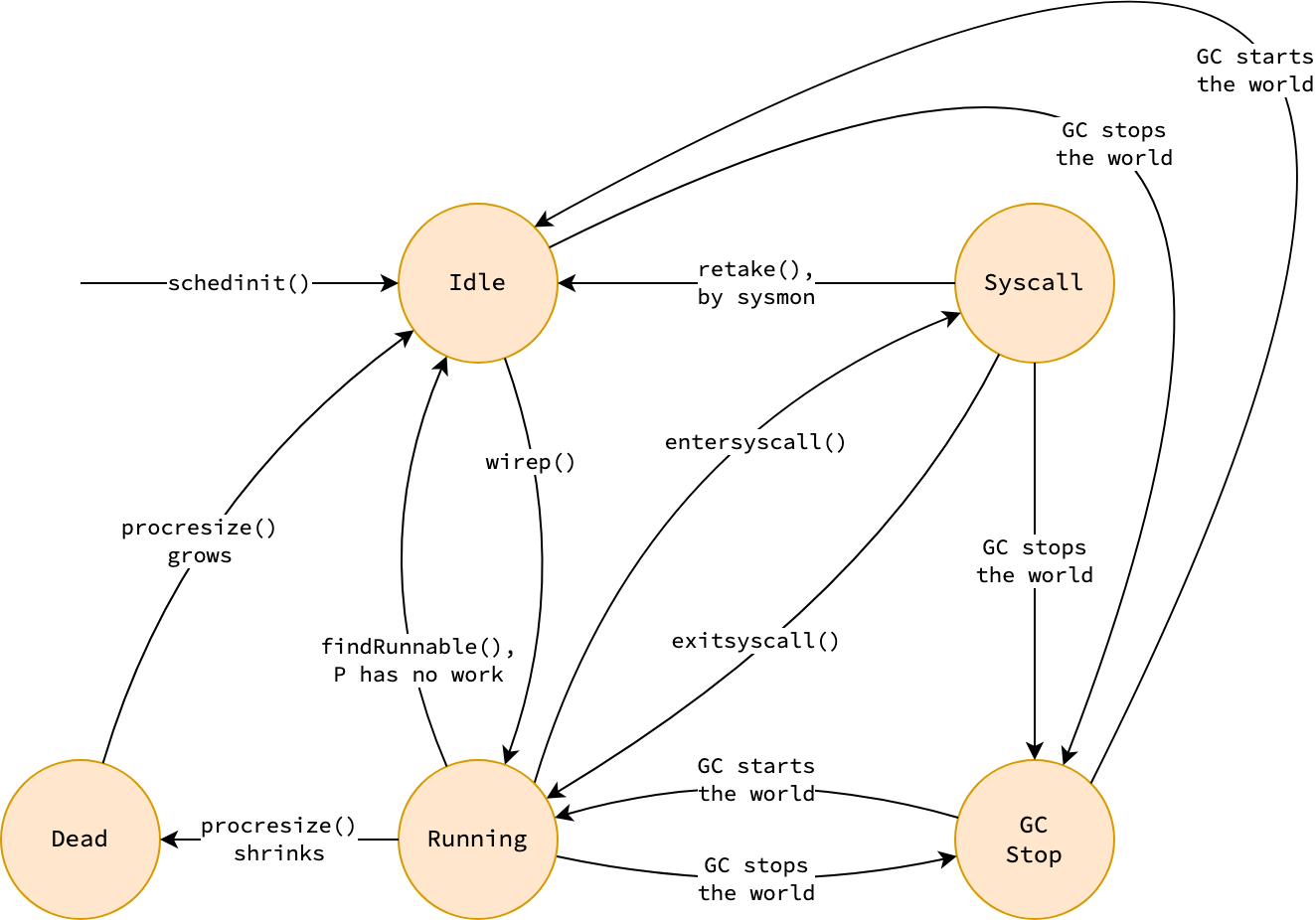
Processor (P) có 5 trạng thái:
| State | Mô tả |
|---|---|
| Idle | Không gắn với M nào, nằm trong idle P list |
| Running | Đang gắn với một M và thực thi goroutine |
| Syscall | M đang trong system call, P tạm thời không được sử dụng và có thể bị steal bởi M khác |
| GCStop | Bị dừng bởi garbage collector trong STW (Stop-The-World) phase |
| Dead | Không còn được sử dụng (khi GOMAXPROCS giảm dynamically) |
Program Bootstrap
Khi một chương trình Go khởi động, runtime thực hiện một chuỗi các bước khởi tạo trước khi user code được chạy:
-
Thread M0 và Goroutine G0 được tạo: M0 là main thread — thread đầu tiên của process. G0 là goroutine đặc biệt gắn với M0, chạy trên system stack. TLS (Thread-Local Storage) được setup để M0 có thể truy cập goroutine hiện tại qua
getg(). -
procresizekhởi tạo Processors: Hàmprocresizetạo ra đúngGOMAXPROCSprocessor, tất cả bắt đầu ở trạng thái Idle. P0 (processor đầu tiên) được gắn ngay với M0. -
Main goroutine thực thi
runtime.main: Runtime tạo main goroutine và đặt vào run queue. Goroutine này thực thiruntime.main, trong đó spawn sysmon trên một dedicated thread riêng — sysmon không cần P để hoạt động. -
runtime.maingọimain.main: Đây là điểm bắt đầu thực sự của user code. Từ đây, chương trình của bạn bắt đầu chạy.
Sysmon
Sysmon là background daemon thread chạy song song với toàn bộ chương trình, đảm nhiệm các tác vụ giám sát quan trọng:
- Preemption: Phát hiện goroutine chạy quá lâu (>10ms) và gửi tín hiệu preempt
- Processor handoff: Khi M bị block trong syscall quá lâu, sysmon tách P ra và giao cho M khác
- Network polling: Định kỳ kiểm tra netpoll để đánh thức goroutine đang chờ I/O
- GC trigger: Hỗ trợ kích hoạt garbage collection khi cần
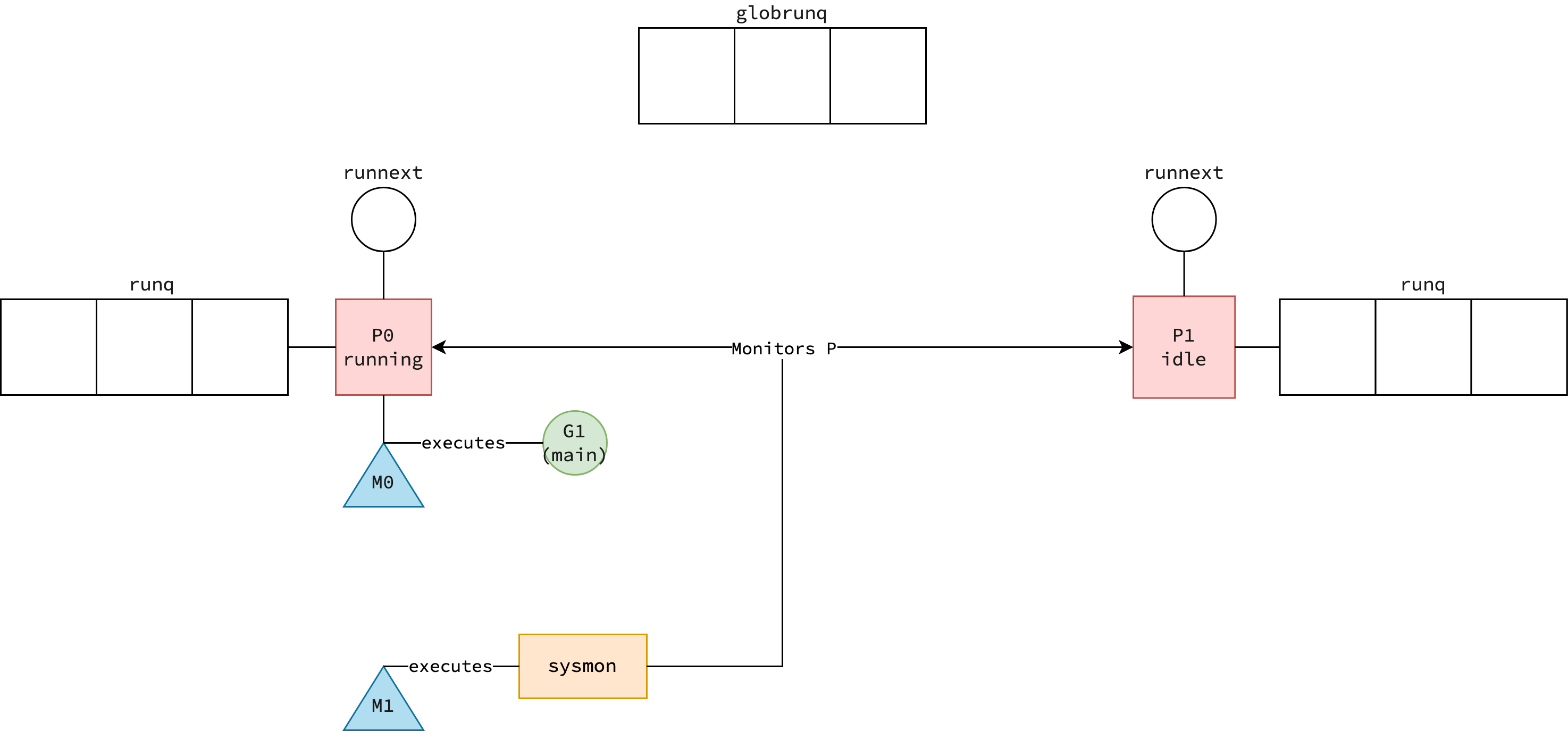
Tạo Goroutine
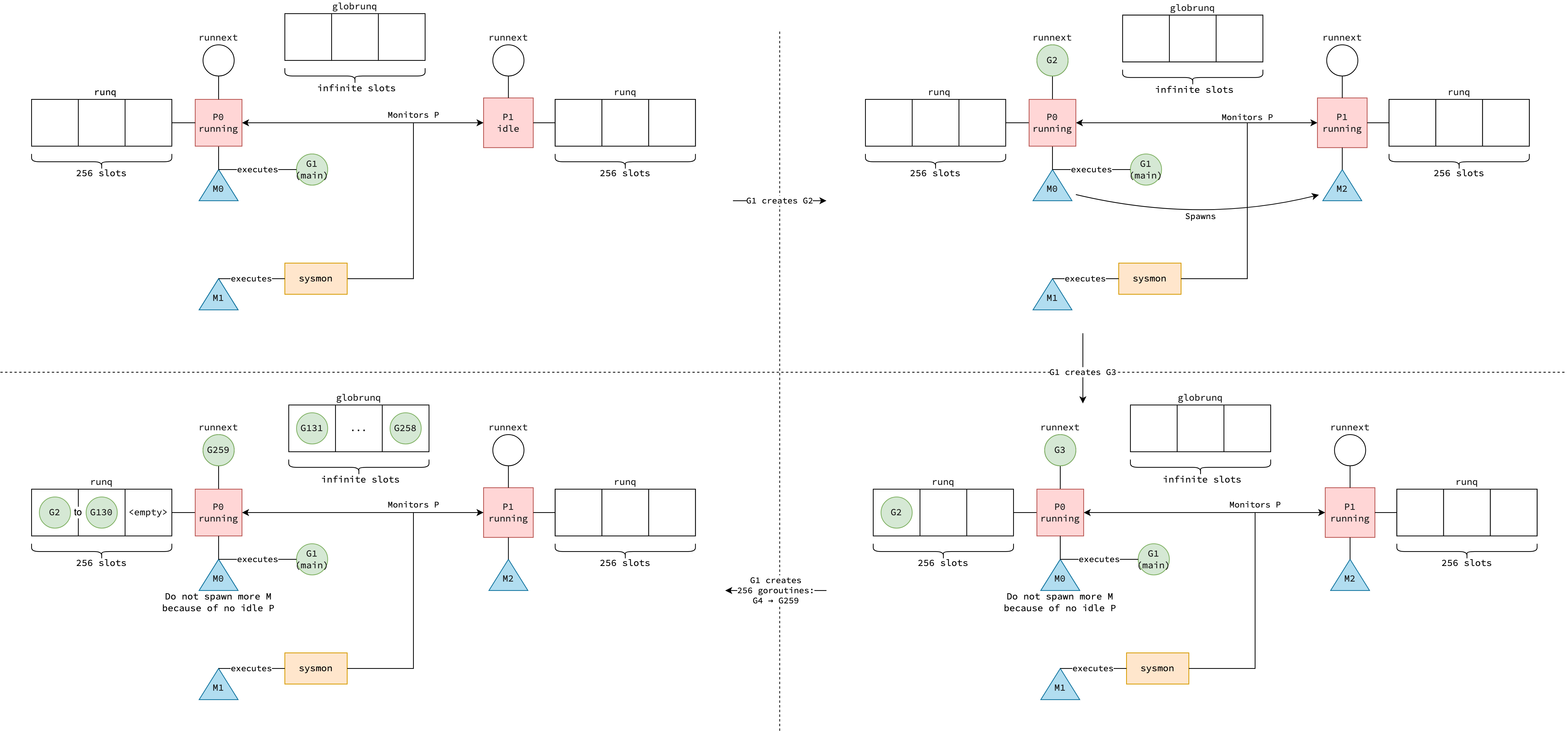
Khi bạn viết go func(), compiler chuyển đổi thành lời gọi runtime.newproc. Quá trình tạo goroutine gồm 3 giai đoạn:
Khởi tạo Goroutine
Runtime ưu tiên lấy goroutine từ free list (recycle) thay vì allocate mới. Goroutine mới nhận stack 2KB và được setup để khi function hoàn thành, nó sẽ return vào goexit.
Hàm goexit được push vào đáy stack — khi goroutine's function return, goexit thực hiện cleanup: đưa G vào free list để recycle và quay lại schedule loop tìm goroutine tiếp theo.
Đưa Goroutine vào Queue
Goroutine mới được đặt vào runnext của P hiện tại — đây là slot có độ ưu tiên cao nhất, goroutine ở đây sẽ được chạy tiếp theo.
Nếu runnext đã có goroutine khác, goroutine cũ bị đẩy xuống runq (local run queue). Nếu runq đã đầy (capacity 256), một nửa số goroutine trong queue sẽ được chuyển sang global run queue để cân bằng tải.
+--------------------------------------------------------------+
| Processor (P) |
| |
| runnext: [new G] <---------- go func() creates new G here |
| |
| runq: [G1][G2]...[G256] |
| | |
| v (if full) |
| half -> global runq |
+--------------------------------------------------------------+
Wake Up Processor
Sau khi goroutine được đưa vào queue, runtime kiểm tra xem có P nào đang idle không. Nếu có, runtime đánh thức một M (hoặc tạo mới nếu cần) để gắn với P đó — nhằm tối đa hóa concurrency.
Việc tạo goroutine mới là trigger chính để đánh thức idle thread. Đây là cơ chế đảm bảo rằng khi có work mới, hệ thống luôn cố gắng tận dụng tối đa số processor khả dụng.
Schedule Loop
Hàm schedule() là trung tâm của Go scheduler — nhiệm vụ chính là tìm và thực thi goroutine sẵn sàng chạy. Hàm này được gọi trong các trường hợp sau:
- Một thread (M) mới được tạo
- Goroutine gọi
runtime.Gosched()để tự nguyện nhường CPU - Goroutine bị park (blocked trên channel, mutex, I/O) hoặc bị preempted
- Sau khi system call hoàn tất
Khi schedule() tìm được một goroutine (G) phù hợp, quá trình diễn ra như sau:
- G chuyển trạng thái từ Runnable sang Running
- Thread gọi hàm
gogo()(được viết bằng assembly) để restore registers và nhảy vào code của G - G bắt đầu thực thi
Vòng lặp Schedule
Điểm quan trọng là schedule loop không bao giờ kết thúc — nó liên tục tìm và chạy goroutine. Khi một goroutine hoàn thành, flow diễn ra:
- Khi tạo goroutine, runtime đã push
goexit()lên stack frame, nên khi G return, nó sẽ tự động gọigoexit() goexit()gọigoexit0()để dọn dẹp: chuyển G state sang Dead, đưa G vào free list để tái sử dụng, và hủy liên kết G-Mgoexit0()gọi lạischedule()— vòng lặp tiếp tục
Schedule Loop
=============
+-> schedule()
| |
| v
| findRunnable() ---> select a G
| |
| v
| execute(G)
| |
| v
| gogo() [assembly] ---> restore registers
| |
| v
| [G runs user code]
| |
| v
| goexit() ---> auto-called when G returns
| |
| v
| goexit0()
| | - G state -> Dead
| | - Put G in free list
| | - Drop G-M association
| |
+-------+
Alternative path (syscall):
[G runs] -> entersyscall() -> [blocked in kernel]
|
v
exitsyscall()
|
v
schedule()
Tim Goroutine de chay (findRunnable)
Hàm findRunnable() thực hiện quá trình tìm kiếm goroutine theo 9 bước ưu tiên. Đây là thuật toán cốt lõi quyết định goroutine nào được chạy tiếp:
Bước 1: Kiểm tra trace reader goroutine
Nếu runtime đang thu thập execution trace (qua runtime/trace package), trace reader goroutine được ưu tiên cao nhất để đảm bảo trace data được xử lý kịp thời.
Bước 2: Kiểm tra GC worker goroutine
Nếu garbage collector đang chạy và cần worker goroutine, GC sẽ được ưu tiên. GC worker thực hiện marking phase — quét object graph để xác định live objects.
Bước 3: Lấy từ global run queue (xác suất 1/61)
Starvation prevention: Cứ mỗi 61 lần gọi
schedule(), hàm sẽ kiểm tra global run queue trước. Nếu không có cơ chế này, goroutine trong global queue có thể bị "bỏ đói" vĩnh viễn vì local queue luôn được kiểm tra trước và có thể luôn có goroutine sẵn sàng.
Con số 61 là số nguyên tố — được chọn để tránh pattern lặp đều đặn và đảm bảo phân phối đều hơn.
Bước 4: Kiểm tra local run queue
Local run queue gồm hai thành phần:
runnext: Một slot duy nhất, chứa goroutine có độ ưu tiên cao nhất. Đây thường là goroutine vừa mới được tạo hoặc vừa được unblock — cho phép nó chạy ngay trên cùng P (tận dụng cache locality)runq: Ring buffer với capacity lên đến 256 goroutine, hoạt động theo FIFO
runnext được kiểm tra trước, sau đó mới đến runq.
Bước 5: Kiểm tra global run queue
Nếu local queue trống, kiểm tra global run queue. Khác với bước 3 (chỉ kiểm tra theo xác suất), bước này kiểm tra vô điều kiện.
Bước 6: Kiểm tra netpoll
Kiểm tra network poller xem có goroutine nào đang chờ I/O đã sẵn sàng hay không. Nếu có socket readable/writable, goroutine tương ứng sẽ được đánh thức.
Bước 7: Work stealing từ P khác
Work stealing: Khi P hết việc, nó sẽ "ăn cắp" goroutine từ local run queue của P khác. Cơ chế này giúp cân bằng tải giữa các processor — tránh tình trạng một P quá tải trong khi P khác idle.
Quá trình steal thực hiện tối đa 4 lần thử (attempts), chọn P victim ngẫu nhiên:
- 3 lần đầu: Chỉ steal từ
runq— lấy một nửa số goroutine trong queue của victim - Lần thứ 4 (lần cuối): Thử steal
runnexttrước, nếu không có thì steal từrunq
Lý do runnext chỉ bị steal ở lần cuối: goroutine trong runnext được kỳ vọng chạy trên P hiện tại để tận dụng CPU cache locality. Chỉ khi thực sự không tìm được goroutine nào khác, scheduler mới steal runnext từ P khác.
Bước 8: Kiểm tra GC worker lần nữa
Kiểm tra lại GC worker một lần nữa — có thể GC đã bắt đầu trong thời gian tìm kiếm.
Bước 9: Kiểm tra global queue lần nữa (nếu M đang spinning)
Spinning thread: Thread đang trong trạng thái tích cực tìm kiếm goroutine. Spinning thread tiêu tốn CPU nhưng đổi lại giảm latency — goroutine mới có thể được chạy ngay lập tức mà không cần đánh thức thread đang ngủ.
Nếu M đang spinning, kiểm tra global queue lần cuối trước khi từ bỏ.
Lấy batch từ global queue
Ở các bước 3, 5 và 9, khi lấy goroutine từ global queue, scheduler lấy theo batch thay vì từng goroutine một:
batch_size = (global_queue_size / num_P) + 1
Giá trị này bị giới hạn (cap) bởi:
- Giá trị max cho phép (tuỳ context)
- Một nửa capacity của local run queue của P (128 goroutine)
Trong batch, một goroutine được trả về trực tiếp để thực thi ngay. Phần còn lại được đưa vào local run queue của P hiện tại.
Khi không tìm được goroutine
Nếu sau 9 bước vẫn không tìm được goroutine nào:
Blocking trên netpoll: M chờ trên network poller cho đến khi timer gần nhất hết hạn hoặc có I/O event. Khi netpoll trả kết quả (có goroutine I/O-ready), M quay lại schedule loop.
Idle state: Nếu P không có timer nào đang chờ:
- P được đưa vào idle P list — danh sách các processor rảnh rỗi
- M đi ngủ bằng
stopm(), sử dụng futex syscall ở mức kernel - Trong trạng thái sleep, M không tiêu tốn CPU — kernel sẽ không schedule thread này cho đến khi nó được đánh thức
- Khi một thread khác tạo goroutine mới hoặc có event cần xử lý, nó sẽ đánh thức M đang ngủ
Goroutine Preemption
Preemption là cơ chế cho phép scheduler dừng một goroutine đang chạy để nhường CPU cho goroutine khác. Nếu không có preemption, một goroutine chạy vòng lặp vô hạn mà không có function call sẽ chiếm giữ P mãi mãi — tất cả goroutine khác trên P đó bị "bỏ đói" và không bao giờ được thực thi.
Preemption: Hành động scheduler dừng goroutine đang chạy (dù chưa hoàn thành) để gán P cho goroutine khác. Go sử dụng hai cơ chế: cooperative preemption (dựa vào function call) và non-cooperative preemption (dựa vào signal).
Non-cooperative Preemption
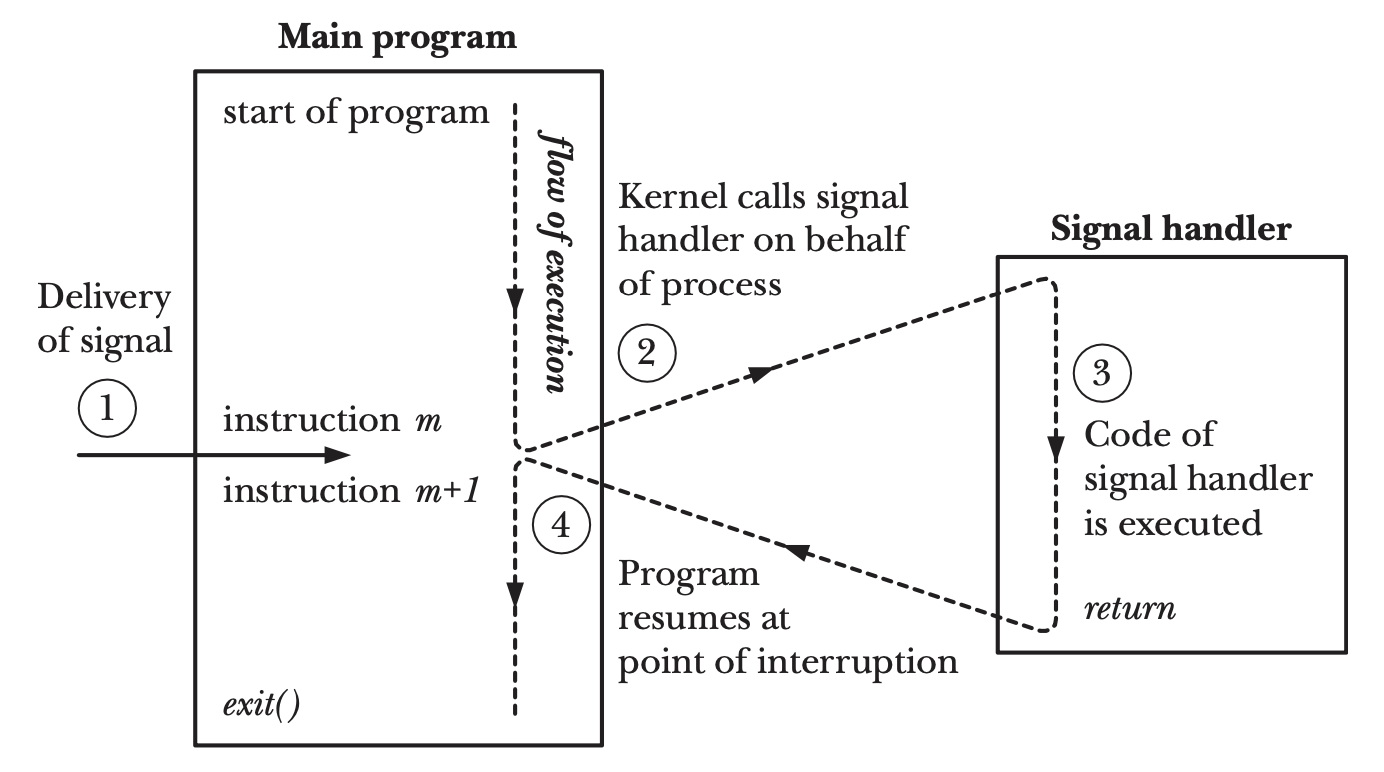
Non-cooperative preemption: Cơ chế preemption không cần sự hợp tác của goroutine. Runtime gửi signal để buộc goroutine dừng ngay lập tức, bất kể goroutine đang thực thi code gì.
sysmon là daemon goroutine chạy trên một dedicated thread riêng — thread này không cần P để hoạt động. sysmon liên tục giám sát tất cả P đang ở trạng thái Running. Khi phát hiện một goroutine sử dụng P liên tục hơn 10ms, quá trình preemption diễn ra:
sysmongửi SIGURG signal đến thread (M) đang chạy goroutine đó, sử dụngtgkillsyscall- Signal handler của thread được kích hoạt, chuyển quyền điều khiển sang
asyncPreempt— hàm assembly lưu toàn bộ register state asyncPreemptgọiasyncPreempt2asyncPreempt2gọigopreempt_m: goroutine bị tách khỏi M và được đưa vào global run queue- Thread quay lại schedule loop để tìm goroutine mới
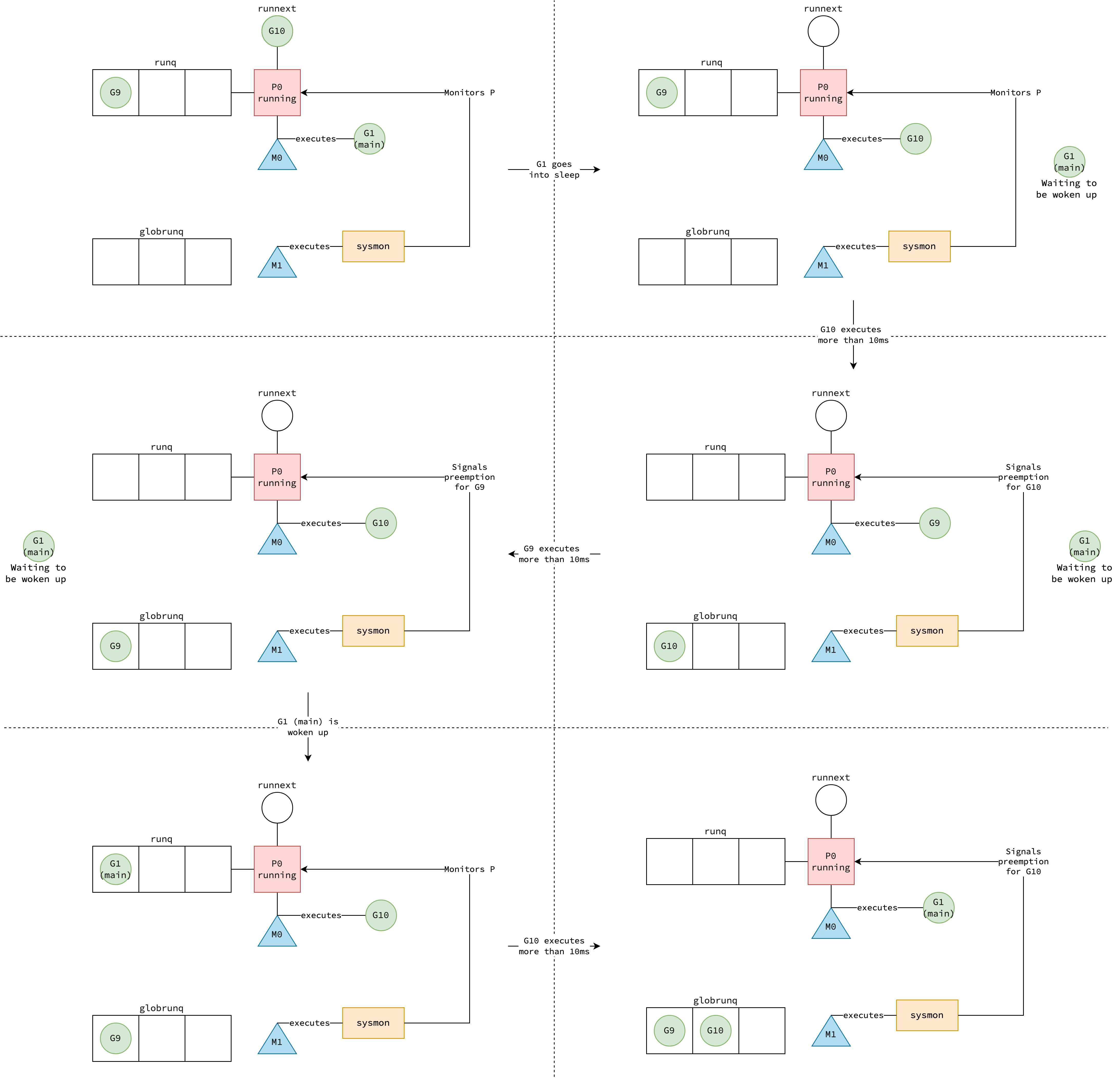
Lưu ý: Vì preemption là asynchronous (signal delivery phụ thuộc vào kernel scheduling), goroutine có thể chạy vượt quá 10ms trước khi thực sự bị interrupt. Thời gian 10ms chỉ là ngưỡng trigger, không phải giới hạn cứng.
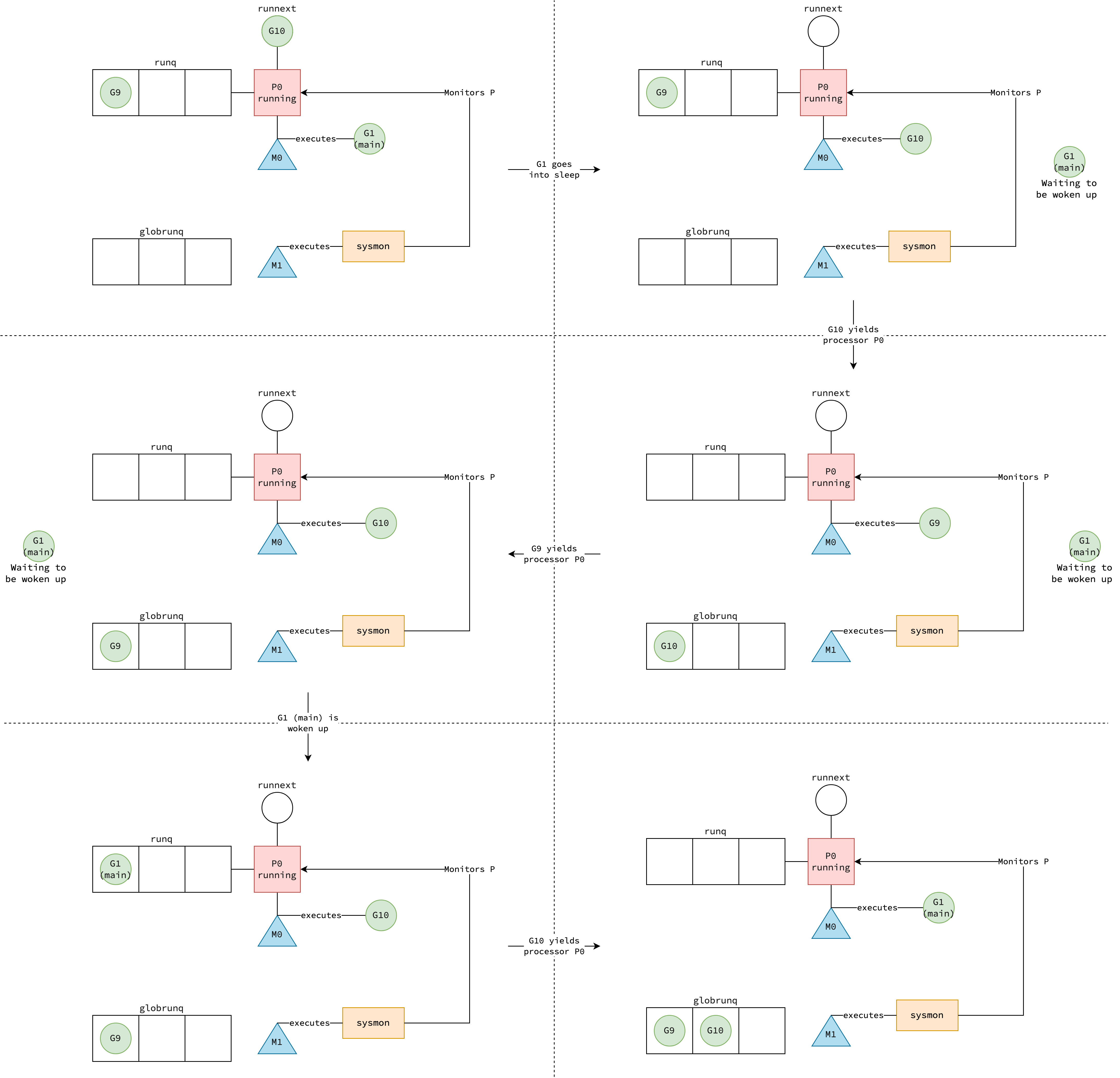
Cooperative Preemption (truoc Go 1.14)
Trước Go 1.14, Go chỉ hỗ trợ cooperative preemption — goroutine chỉ bị preempt khi nó chủ động nhường CPU bằng cách gọi runtime.Gosched(). Trong các vòng lặp chặt (tight loop), developer phải tự thêm runtime.Gosched():
for {
// Compute-intensive work...
runtime.Gosched() // Manually yield to scheduler
}
Cách tiếp cận này có nhiều hạn chế:
- Tedious: Developer phải nhớ thêm
Gosched()vào mọi tight loop - Error-prone: Quên thêm sẽ gây starvation cho goroutine khác
- Performance issues: Mỗi
Gosched()là một context switch, nếu gọi quá thường xuyên sẽ giảm throughput
Cooperative Preemption (Go 1.14+)
Từ Go 1.14, compiler chèn stack guard check vào phần đầu (prologue) của mọi function. Khi goroutine gọi bất kỳ function nào, quá trình kiểm tra diễn ra:
- Function prologue load giá trị
stackguard0từ G struct - So sánh
stackguard0với stack pointer hiện tại - Nếu
stackguard0 == stackPreempt(giá trị đặc biệt): nhảy sangmorestack_noctxt->newstack->gopreempt_m
Khi sysmon phát hiện goroutine chạy quá 10ms, nó set stackguard0 = stackPreempt. Lần gọi function tiếp theo sẽ trigger preemption tự động.
Ví dụ assembly trên ARM64 cho function prologue:
MOVD 16(R28), R16 # Load stackguard0 from G struct
SUB $48, RSP, R17 # Calculate stack frame limit
CMP R16, R17 # Compare stackguard0 with stack pointer
BLS 96(PC) # Branch to morestack if overflow/preempt
Giải thích:
R28trỏ đến G struct hiện tạistackguard0nằm ở offset 16 trong G struct- Nếu
stackguard0được set thànhstackPreempt(giá trị rất lớn), phép so sánh sẽ luôn fail -> nhảy vàomorestack-> trigger preemption
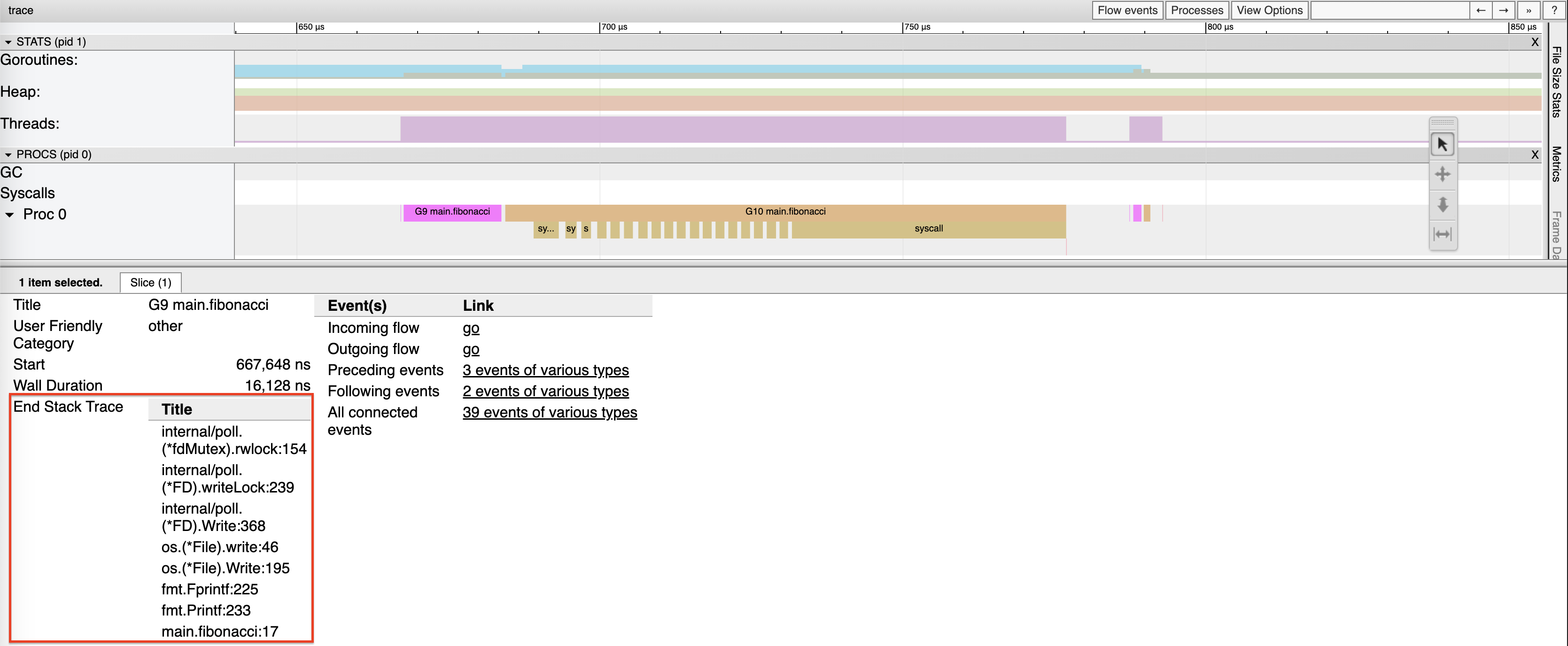
So sanh qua Runtime Trace
Sự khác biệt giữa hai cơ chế có thể quan sát rõ ràng qua Go runtime trace:

Non-cooperative preemption: Goroutine chạy liên tục 10ms+ trước khi bị signal interrupt. Trace hiển thị các block dài trên mỗi P, cho thấy goroutine chiếm giữ P trong khoảng thời gian đáng kể trước khi yield.
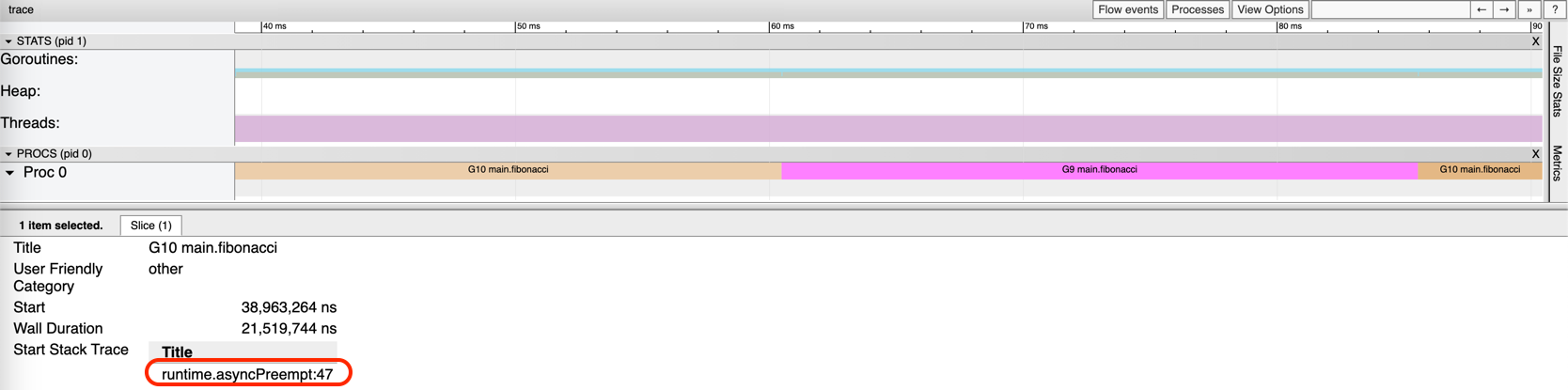
Cooperative preemption: Goroutine yield tại mỗi function call boundary (ví dụ fmt.Printf). Trace hiển thị các block rất ngắn (microsecond-level), cho thấy goroutine chuyển đổi nhanh chóng.
Tai sao can ca hai co che?
Cả hai cơ chế preemption tồn tại song song vì chúng bổ sung cho nhau:
-
Cooperative preemption xử lý phần lớn trường hợp — vì function call rất thường xuyên trong code Go thông thường. Cơ chế này nhẹ hơn (chỉ cần kiểm tra stack guard, không cần signal) và cho phép preemption tại safe points nơi goroutine state nhất quán.
-
Non-cooperative preemption là lưới an toàn cho các tight loop không có function call — ví dụ
for {}hoặc các vòng lặp tính toán thuần tuý chỉ thao tác trên biến local. Nếu không có cơ chế này, những goroutine như vậy sẽ chiếm giữ P vĩnh viễn và không bao giờ bị preempt.
Kết hợp cả hai đảm bảo scheduler luôn có khả năng lấy lại quyền điều khiển, bất kể goroutine đang thực thi loại code nào.
Handling System Calls
System Call (syscall): Là các services do kernel cung cấp cho user-space programs — bao gồm đọc file, thiết lập network connection, allocate memory, và nhiều thao tác khác. Go standard library abstract phần lớn syscalls, nhưng hiểu cách chúng hoạt động là chìa khóa để nắm rõ Go runtime internals.
Phân loại System Call
Go runtime cung cấp hai wrappers cho system calls, phân biệt theo thời gian thực thi dự kiến:
RawSyscall: Wrapper thực hiện syscall trực tiếp mà không thông báo cho scheduler. Dùng cho các syscall nhanh, thời gian thực thi có thể dự đoán được — ví dụ
getpid,gettime.
Syscall: Wrapper bọc
RawSyscallvới logic thông báo scheduler trước và sau khi thực hiện. Dùng cho các syscall có thời gian thực thi không thể dự đoán — ví dụread,write,connect.
func Syscall(trap, a1, a2, a3 uintptr) (r1, r2 uintptr, err Errno) {
runtime_entersyscall()
r1, r2, err = RawSyscall6(trap, a1, a2, a3, 0, 0, 0)
runtime_exitsyscall()
}
Cấu trúc rất rõ ràng: Syscall bọc RawSyscall với hai hàm runtime_entersyscall() và runtime_exitsyscall() — thông báo cho scheduler biết goroutine đang vào và ra khỏi syscall, để scheduler có thể điều phối tài nguyên hợp lý.
Scheduling trong Syscall
Trước khi syscall (runtime_entersyscall -> reentersyscall)
Khi goroutine chuẩn bị thực hiện syscall, runtime thực hiện các bước sau:
- G chuyển state: Running -> Syscall
- Lưu execution context: Save SP (stack pointer), PC (program counter), FP (frame pointer) để khôi phục sau khi syscall hoàn thành
- M tách khỏi P: M detaches khỏi P hiện tại, P chuyển sang trạng thái Syscall
+--------------+ entersyscall +--------------+
| G: Running | ----------> | G: Syscall |
| M: has P | | M: no P |
| P: Running | | P: Syscall |
+--------------+ +--------------+
sysmon monitoring
sysmon: Là một system goroutine chạy trên background thread riêng, liên tục monitor trạng thái của tất cả P trong hệ thống.
Khi sysmon phát hiện một P ở trạng thái Syscall quá lâu (> 10ms), nó thực hiện processor handoff — gắn P đó cho một M khác (M1) để các goroutine runnable trong local run queue của P tiếp tục được thực thi.
Lưu ý quan trọng: Đây là processor handoff, không phải preemption. M ban đầu vẫn bị block cùng G trong syscall — vì thread (M) là đơn vị thực thi của kernel, M thực hiện syscall thay mặt cho G, nên association giữa M và G được duy trì cho đến khi syscall hoàn thành.
Tại sao điều này quan trọng? P trong trạng thái Syscall không thể được sử dụng bởi M khác cho đến khi sysmon seize nó hoặc syscall hoàn thành. Nếu nhiều goroutines cùng thực hiện syscall đồng thời và tất cả P đều bị lock trong trạng thái Syscall, chương trình sẽ không thể tiến triển (no progress). Đây là lý do tại sao Dgraph hardcode GOMAXPROCS=128 — tăng số lượng P để có nhiều processor hơn cho disk I/O scheduling.
Sau khi syscall (runtime_exitsyscall)
Khi syscall hoàn thành, runtime cố gắng đưa goroutine trở lại trạng thái Running thông qua hai đường dẫn:
Fast path: Có P available — P gốc vẫn ở trạng thái Syscall (sysmon chưa seize), hoặc tìm được idle P bất kỳ. G chuyển state: Syscall -> Running, tiếp tục thực thi ngay lập tức.
Slow path: Không có P nào available. Runtime thử lấy idle P thêm một lần nữa:
- Nếu tìm được idle P: schedule G trên P đó
- Nếu không tìm được: G được đưa vào global run queue, M đi ngủ thông qua
stopm
exitsyscall
|
+--------+--------+
| |
Fast path Slow path
| |
P available? Try idle P again
Yes | | |
v Found P No P
G: Running | |
Schedule G G -> global queue
on P M -> stopm (sleep)
Network I/O và Netpoll
Theo Go Developer Survey, khoảng 75% use cases của Go là web services. Go được thiết kế từ đầu để giải quyết C10K problem một cách hiệu quả — xử lý hàng chục nghìn concurrent connections trên một server.
C10K Problem: Bài toán kỹ thuật kinh điển về việc làm sao một server có thể xử lý 10,000 concurrent connections. Các giải pháp truyền thống dựa trên thread-per-connection không scale được do overhead của OS threads.
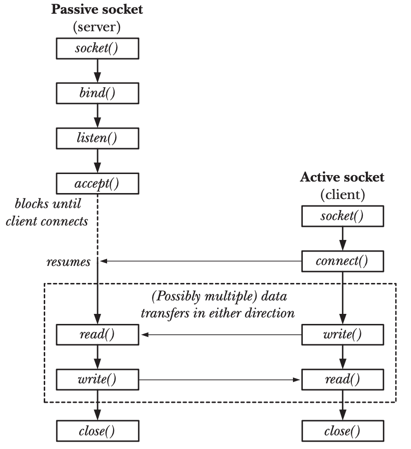
HTTP Server Under the Hood
Khi bạn viết một HTTP server đơn giản với http.ListenAndServe(), Go abstract rất nhiều syscalls phía sau:
- Server setup:
socket()->bind()->listen()->accept()— tạo socket, bind address, listen và accept connections - Request handling:
http.HandleFunc()abstract các syscallread()vàwrite()cho mỗi connection

I/O Models
Để hiểu cách Go xử lý network I/O, trước tiên cần nắm 3 I/O models cơ bản:
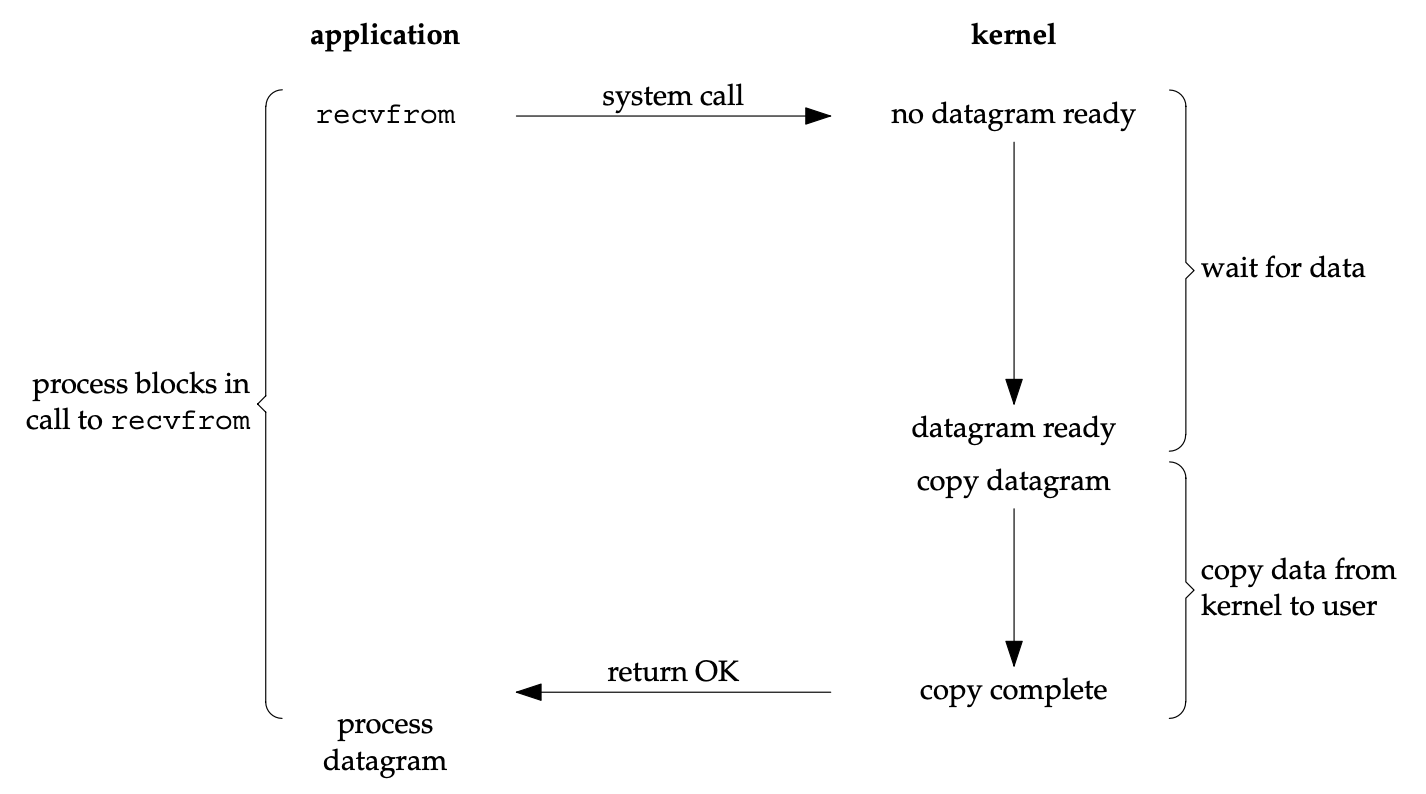
Blocking I/O: Thread bị suspend cho đến khi data sẵn sàng. Đơn giản nhưng cần N threads cho N connections — không scale.
Non-blocking I/O: Syscall trả về ngay lập tức với data (nếu có) hoặc error
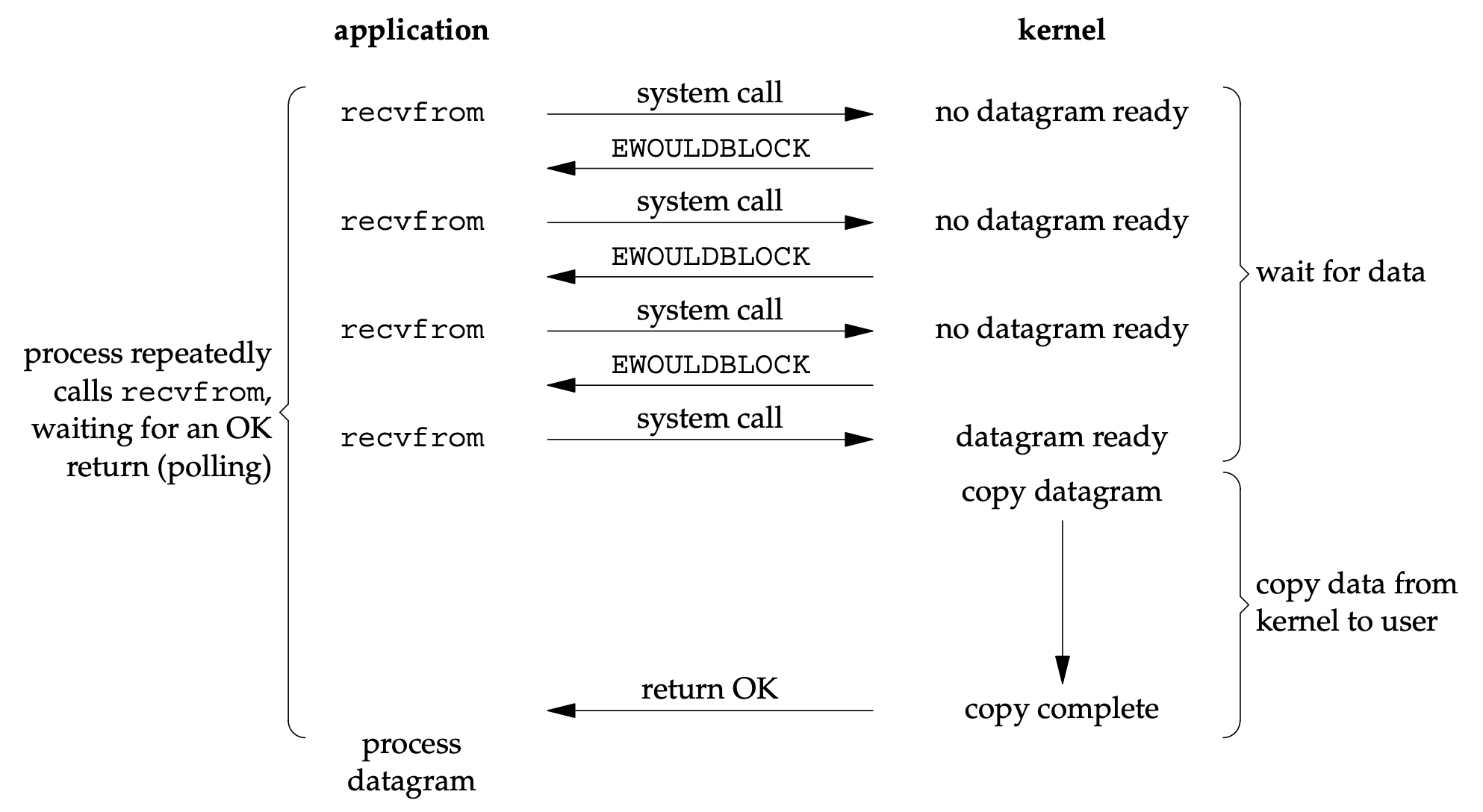
EAGAIN(nếu chưa sẵn sàng). Hiệu quả nhưng phức tạp khi phải liên tục polling.
I/O Multiplexing: Sử dụng
select/poll/epollđể theo dõi nhiều file descriptors cùng lúc. Application block trênselectthay vì block trên từng I/O operation riêng lẻ.
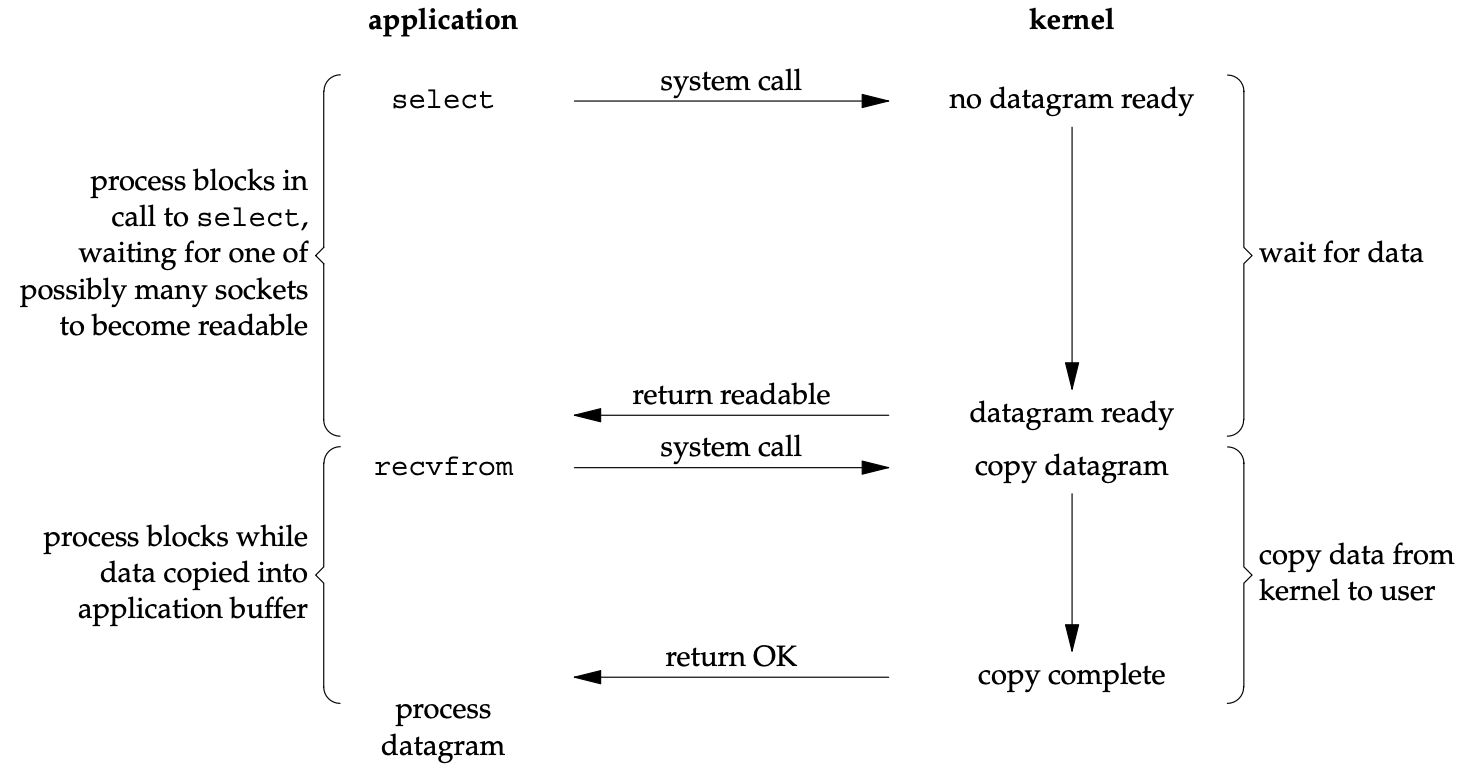
I/O Model trong Go
Go kết hợp non-blocking I/O với I/O multiplexing để đạt hiệu suất cao nhất. Tuy nhiên, Go không sử dụng select/poll truyền thống (vì performance giảm khi số lượng file descriptors lớn). Thay vào đó, Go sử dụng các platform-specific mechanisms:
| Platform | Mechanism |
|---|---|
| Linux | epoll |
| Darwin (macOS) | kqueue |
| Windows | IOCP (I/O Completion Ports) |
Tất cả được abstract thông qua netpoll function trong runtime — cho phép Go code viết theo blocking style nhưng thực tế chạy non-blocking phía sau.
Cách Netpoll hoạt động
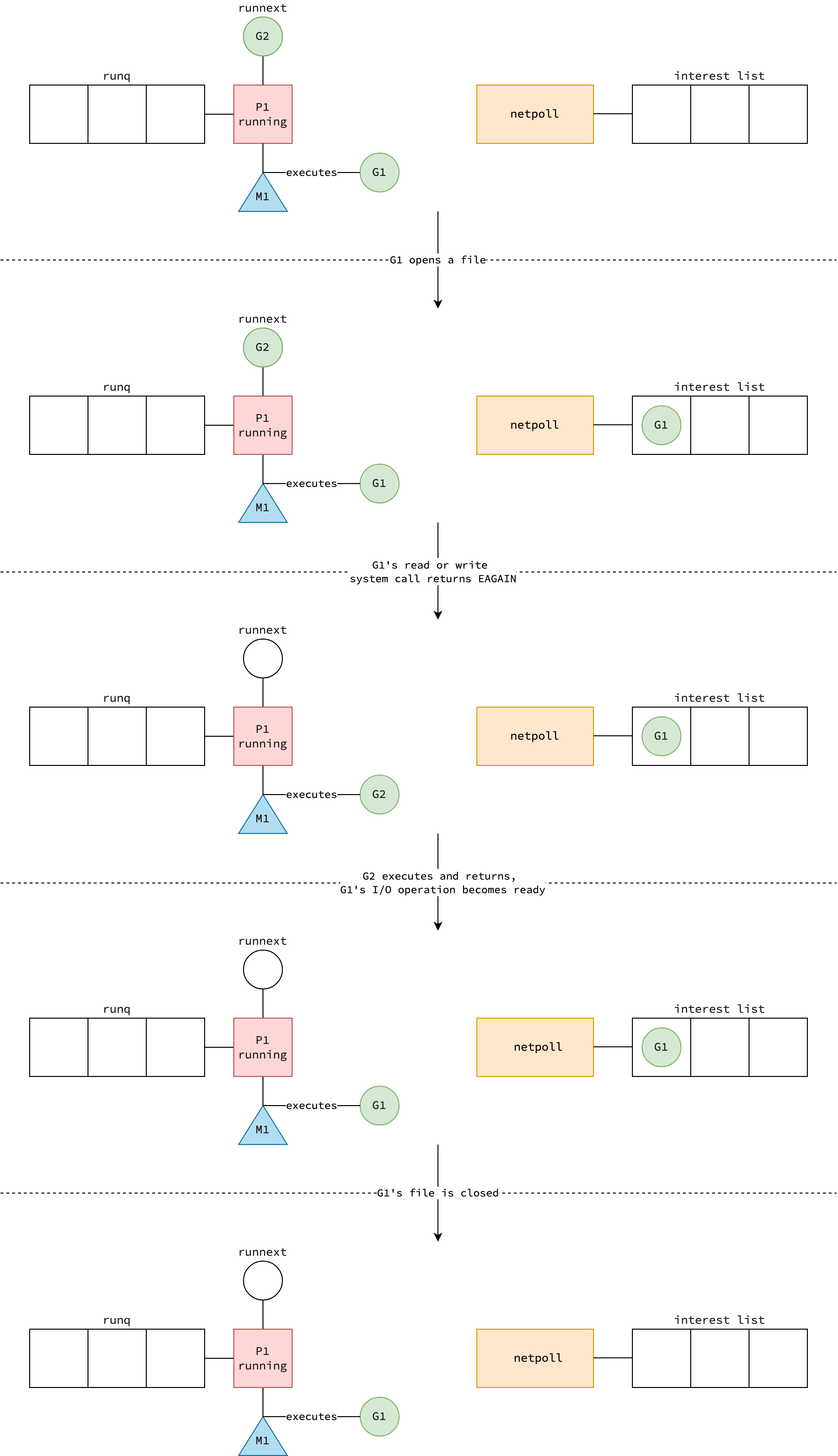
Step 1: Tạo epoll instance và đăng ký goroutine
Khi Go accept một TCP connection, socket được tạo với flag SOCK_NONBLOCK để đảm bảo non-blocking I/O. Quá trình đăng ký diễn ra như sau:
net.netFDwraps file descriptor -> triggerepoll_create(thông quasync.Once— chỉ tạo một epoll instance duy nhất cho toàn bộ process lifetime)runtime.pollDescđược allocate chứa scheduling metadata và G references -> gọiepoll_ctlvớiEPOLL_CTL_ADDđể đăng ký FD vào epoll instancepoll.FDquản lý read/write operations với polling support
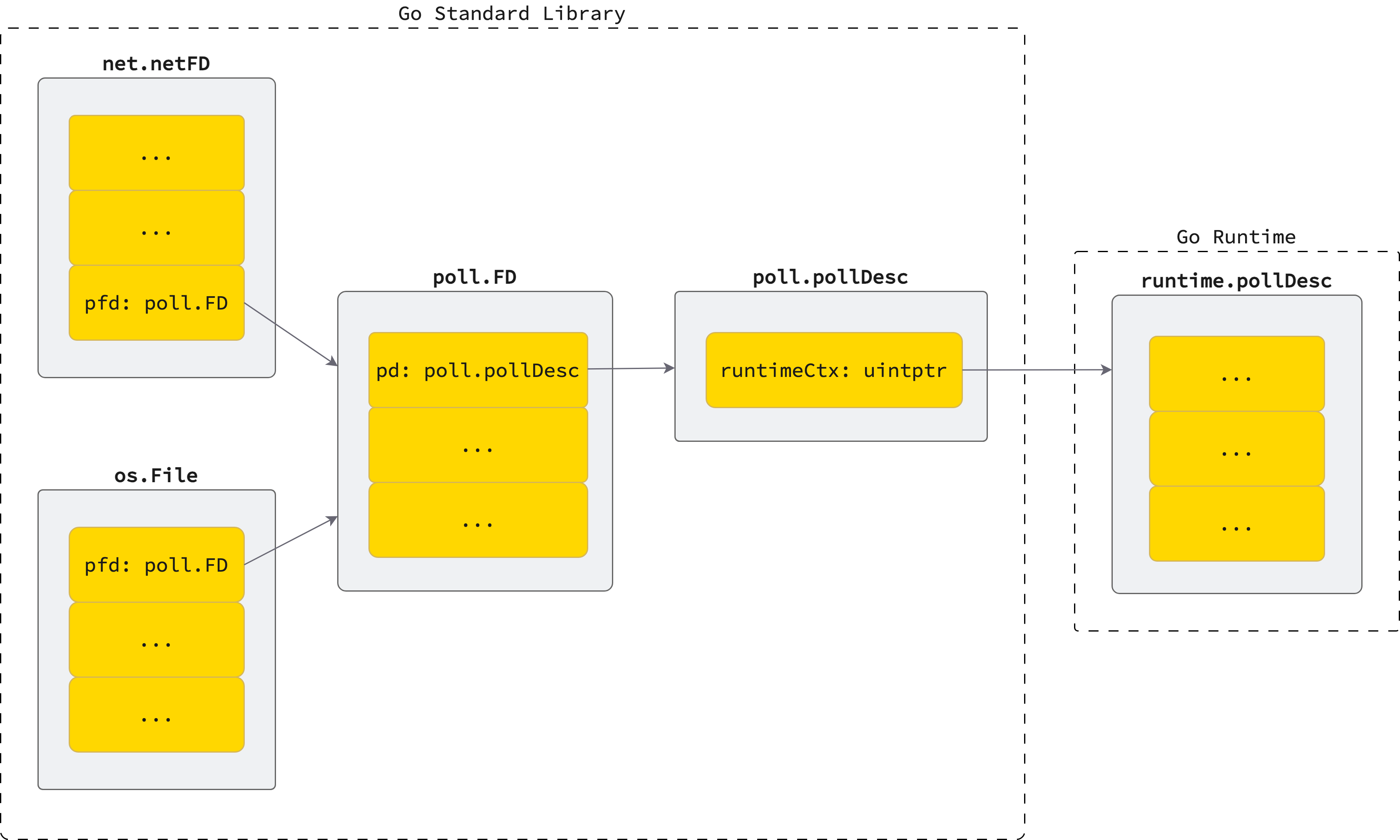
Lưu ý: Việc chỉ sử dụng một epoll instance duy nhất có known issues (Go issue #65064). Hiện đang có discussions về việc sử dụng multiple epoll instances hoặc chuyển sang io_uring.
Go cũng sử dụng epoll cho file I/O: gọi SetNonblock để chuyển FD sang non-blocking mode, sau đó đăng ký vào cùng epoll instance.
Step 2: Polling file descriptors
Khi goroutine thực hiện read operation:
poll.FD.Readgọireadsyscall- Nếu trả về
EAGAIN(data chưa sẵn sàng) ->poll_runtime_pollWaitpark goroutine (chuyển sang Waiting state) netpollfunction gọiepoll_waitđể monitor tối đa 128 file descriptors cùng lúc- Khi data sẵn sàng,
epoll_waittrả vềruntime.pollDesccủa các FD đã ready - Runtime extract G references từ
pollDescvà đưa các goroutine này trở lại runnable state
Khi nào netpoll được gọi? Trong findRunnable, runtime chỉ consult netpoll khi không tìm thấy goroutine nào trong local run queue và global run queue.
delay parameter của netpoll:
- Positive value: Block tối đa N nanoseconds
- Negative value: Block cho đến khi có FD ready (used in sysmon)
- Zero: Return ngay lập tức (used in
findRunnable)
Step 3: Unregister file descriptors
Khi connection được close:
poll.FD.destroygọipoll_runtime_pollClosepoll_runtime_pollClosegọiepoll_ctlvớiEPOLL_CTL_DELđể remove FD khỏi epoll instance
Quan trọng: Phải unregister FD khi close connection để tránh FD leak và goroutine starvation — nếu FD không được unregister, goroutine đang chờ data trên FD đó sẽ không bao giờ được wake up.
Garbage Collector
Go sử dụng tracing GC với thuật toán tri-color marking. GC chạy concurrent với chương trình — giảm thiểu thời gian STW (Stop-The-World) pauses.
Tri-color Marking: Thuật toán GC chia objects thành 3 nhóm: white (chưa visited, có thể là garbage), gray (đã visited nhưng chưa scan references), và black (đã visited và đã scan tất cả references). Objects còn white sau khi marking hoàn thành sẽ bị sweep.
GC hoạt động qua 4 phases:
| Phase | Mô tả | Concurrent? |
|---|---|---|
| First STW | Tất cả P pause tại safe points | Không — STW |
| Marking | GC goroutines chạy concurrent với regular Gs trên cùng P | Có |
| Second STW | Finalize marking, đảm bảo tất cả objects được scan | Không — STW |
| Sweeping | Background memory reclamation | Có |
Trong findRunnable, runtime tìm kiếm cả regular goroutines và GC goroutines (steps 2 và 8 trong schedule loop) — đảm bảo GC work được thực hiện song song với application code.
Các Runtime Functions quan trọng
getg()
getg(): Lấy pointer đến goroutine struct (G) hiện tại. Không có Go implementation — compiler thay thế bằng instruction đọc G từ TLS hoặc dedicated register.
getg() không có source code nào implement. Compiler nhận diện function này và thay thế trực tiếp bằng machine instruction đọc G pointer từ:
- TLS (Thread-Local Storage) trên một số platforms
- Dedicated register trên platforms khác
G pointer được lưu vào TLS/register trong hai trường hợp:
- Khi context switch qua
gogo()— chuyển execution sang goroutine khác - Khi signal handler qua
sigtrampgo— xử lý OS signals
gopark()
gopark(): Park goroutine hiện tại — chuyển từ Running sang Waiting state. Goroutine sẽ không được schedule cho đến khi được explicitly unpark (ví dụ bởi channel send, mutex unlock, hoặc timer).
Quy trình hoạt động:
- Set
stackguard0 = stackPreempt— đánh dấu goroutine cần được preempt - Chuyển execution sang g0 thông qua
mcall(park_m) - Drop association giữa G và M — G không còn gắn với M nào
- Gọi
unlockfcallback:- Return
false: G được reschedule ngay lập tức (useful khi condition đã thay đổi) - Return
true: M vào schedule loop, tìm goroutine khác để chạy
- Return
func gopark(unlockf func(*g, unsafe.Pointer) bool, ...) {
mp.waitunlockf = unlockf
releasem(mp)
mcall(park_m)
}
startm()
startm(): Schedule một M để chạy P. Đảm bảo mọi P có work đều có M tương ứng để thực thi.
Quy trình:
- Nếu P parameter là nil -> lấy idle P từ global list
- Nếu không có idle P -> return (tất cả processors đang busy)
- Với P available:
- Tìm idle M trong idle list -> wake up bằng
futex - Nếu không có idle M -> tạo thread mới bằng
clonesyscall vớimstartentry point
- Tìm idle M trong idle list -> wake up bằng
stopm()
stopm(): Đưa M vào trạng thái sleep — thêm M vào idle list và suspend bằng
futexsyscall. M không tiêu tốn CPU khi sleeping.
stopm không return cho đến khi M được đánh thức — thường xảy ra khi có goroutine mới được tạo (qua newproc) hoặc khi có P cần M để chạy.
handoffp()
handoffp(): Transfer P từ M đang bị block sang M khác (M1). Đảm bảo P không bị idle khi vẫn còn work cần thực hiện.
handoffp kiểm tra các conditions sau để quyết định có cần transfer P hay không:
- Global run queue non-empty
- Local run queue non-empty
- Tracing hoặc GC work cần thực hiện
- Không có thread nào handles netpoll
Nếu không có condition nào thỏa mãn — P được trả về idle list.
GOMAXPROCS
GOMAXPROCS: Số lượng P (logical processors) tối đa mà Go runtime sử dụng. Xác định bao nhiêu goroutines có thể chạy thực sự parallel.
runtime.GOMAXPROCS(n) set số lượng P. Mặc định bằng runtime.NumCPU() — query số CPU cores từ OS.
Vấn đề trong containers: Mặc định, runtime.NumCPU() query từ OS và trả về tổng số CPU cores của host machine, không phải cgroup limits. Điều này có thể gây ra vấn đề trong containerized environments. Hiện có ongoing proposal để Go tự động respect cgroup CPU limits.
"This call will go away when the scheduler improves." — Go documentation
Dgraph hardcode GOMAXPROCS=128 để có nhiều P hơn cho I/O scheduling — cho phép nhiều goroutines thực hiện disk I/O đồng thời mà không bị block lẫn nhau.
Goexit
runtime.Goexit(): Gracefully terminate goroutine hiện tại. Tất cả deferred functions được thực thi trước khi goroutine kết thúc. Các goroutines khác tiếp tục chạy bình thường.
Đặc điểm quan trọng:
- Tất cả
defercalls được execute theo thứ tự LIFO trước khi goroutine exit - Các goroutines khác không bị ảnh hưởng
- Nếu tất cả goroutines exit (bao gồm main goroutine), chương trình crash
- Useful trong testing: abort test sớm nhưng vẫn đảm bảo deferred cleanup chạy đúng
Tổng kết
Go Scheduler cho phép lightweight concurrency thông qua mô hình GMP:
- G (Goroutine): Lightweight execution unit, 2KB stack, được recycle khi hoàn thành
- M (Machine/Thread): OS thread thực sự, có g0 riêng để chạy scheduler code
- P (Processor): Quản lý local run queue và mcache, số lượng =
GOMAXPROCS
Các cơ chế chính:
| Cơ chế | Mô tả |
|---|---|
| Preemption | Non-cooperative (SIGURG signal) + cooperative (stack guard check) |
| Work Stealing | Idle threads steal goroutines từ local run queue của P khác |
| Netpoll | epoll-based I/O multiplexing, cho phép blocking-style code chạy non-blocking |
| Syscall Handling | Processor handoff giữ P busy trong khi M bị block trong syscall |
| GC Integration | Concurrent marking với minimal STW pauses |
Sự kết hợp của các cơ chế này cho phép Go xử lý hàng triệu goroutines hiệu quả, với overhead thấp và latency ổn định — đặc biệt phù hợp cho web services, microservices, và distributed systems.
References
- Go Scheduler - nghiant3223
- Go Scheduling - kelche.co
- Preemption in Go: An Introduction - unskilled.blog
- Go Runtime Source Code (go1.24.0)
- Scalable Go Scheduler Design Doc - Dmitry Vyukov
- The Linux Programming Interface - Michael Kerrisk
- Unix Network Programming - W. Richard Stevens
- Operating System Concepts - Silberschatz, Galvin, Gagne
Bài viết liên quan
- Deep Dive: Goroutines, Threads, and Processes in Go - Khám phá sâu goroutines, threads và processes trong Go